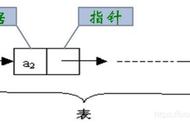
双向链表示意图
一个完整的双向链表应该是头结点的pre指针指为空,尾结点的next指针指向空,其余结点前后相连。
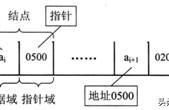
双向链表的结点设计对于每一个结点而言,有:

其中,DATA表示数据,其可以是简单的类型也可以是复杂的结构体;
pre代表的是前驱指针,它总是指向当前结点的前一个结点,如果当前结点是头结点,则pre指针为空;
next代表的是后继指针,它总是指向当前结点的下一个结点,如果当前结点是尾结点,则next指针为空
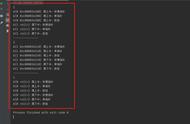
其代码设计如下:
typedefstructline{
intdata;//data
structline*pre;//prenode
structline*next;//nextnode
}line,*a;
//分别表示该结点的前驱(pre),后继(next),以及当前数据(data)
- 双链表的创建
创建双向链表需要先创建头结点,然后逐步的进行添加双向链表的头结点是有数据元素的,也就是头结点的data域中是存有数据的,这与一般的单链表是不同的。
对于逐步添加数据,先开辟一段新的内存空间作为新的结点,为这个结点进行的data进行赋值,然后将已成链表的上一个结点的next指针指向自身,自身的pre指针指向上一个结点。
其代码可以设计为:
//创建双链表
line*initLine(line*head){
intnumber,pos=1,input_data;
//三个变量分别代表结点数量,当前位置,输入的数据
printf("请输入创建结点的大小\n");
scanf("%d",&number);
if(number<1){returnNULL;}//输入非法直接结束
//////头结点创建///////
head=(line*)malloc(sizeof(line));
head->pre=NULL;
head->next=NULL;
printf("输入第%d个数据\n",pos );
scanf("%d",&input_data);
head->data=input_data;
line*list=head;
while(pos<=number){
line*body=(line*)malloc(sizeof(line));
body->pre=NULL;
body->next=NULL;
printf("输入第%d个数据\n",pos );
scanf("%d",&input_data);
body->data=input_data;
list->next=body;
body->pre=list;
list=list->next;
}
returnhead;
}
双向链表创建的过程可以分为:创建头结点->创建一个新的结点->将头结点和新结点相互链接->再度创建新结点,这样会有助于理解。
双向链表的插入操作如图所示:

对于每一次的双向链表的插入操作,首先需要创建一个独立的结点,并通过malloc操作开辟相应的空间;
其次我们选中这个新创建的独立节点,将其的pre指针指向所需插入位置的前一个结点;
同时,其所需插入的前一个结点的next指针修改指向为该新的结点,该新的结点的next指针将会指向一个原本的下一个结点,而修改下一个结点的pre指针为指向新结点自身,这样的一个操作我们称之为双向链表的插入操作。
其代码可以表示为:
//插入数据
line*insertLine(line*head,intdata,intadd){
//三个参数分别为:进行此操作的双链表,插入的数据,插入的位置
//新建数据域为data的结点
line*temp=(line*)malloc(sizeof(line));
temp->data=data;
temp->pre=NULL;
temp->next=NULL;
//插入到链表头,要特殊考虑
if(add==1){
temp->next=head;
head->pre=temp;
head=temp;
}else{
line*body=head;
//找到要插入位置的前一个结点
for(inti=1;i<add-1;i ){
body=body->next;
}
//判断条件为真,说明插入位置为链表尾
if(body->next==NULL){
body->next=temp;
temp->pre=body;
}else{
body->next->pre=temp;
temp->next=body->next;
body->next=temp;
temp->pre=body;
}
}
returnhead;
}
双向链表的删除操作
如图:

删除操作的过程是:选择需要删除的结点->选中这个结点的前一个结点->将前一个结点的next指针指向自己的下一个结点->选中该节点的下一个结点->将下一个结点的pre指针修改指向为自己的上一个结点。
在进行遍历的时候直接将这一个结点给跳过了,之后,我们释放删除结点,归还空间给内存,这样的操作我们称之为双链表的删除操作。
其代码可以表示为:
//删除元素
line*deleteLine(line*head,intdata){
//输入的参数分别为进行此操作的双链表,需要删除的数据
line*list=head;
//遍历链表
while(list){
//判断是否与此元素相等
//删除该点方法为将该结点前一结点的next指向该节点后一结点
//同时将该结点的后一结点的pre指向该节点的前一结点
if(list->data==data){
list->pre->next=list->next;
list->next->pre=list->pre;
free(list);
printf("--删除成功--\n");
returnhead;
}
list=list->next;
}
printf("Error:没有找到该元素,没有产生删除\n");
returnhead;
}
双向链表的遍历
双向链表的遍历利用next指针逐步向后进行索引即可。
注意,在判断这里,我们既可以用while(list)的操作直接判断是否链表为空,也可以使用while(list->next)的操作判断该链表是否为空,其下一节点为空和本结点是否为空的判断条件是一样的效果。
其简单的代码可以表示为:
//遍历双链表,同时打印元素数据
voidprintLine(line*head){
line*list=head;
intpos=1;
while(list){
printf("第%d个数据是:%d\n",pos ,list->data);
list=list->next;
}
}
循环链表循环链表概念
对于单链表以及双向链表,就像一个小巷,无论怎么走最终都能从一端走到另一端,顾名思义,循环链表则像一个有传送门的小巷,当你以为你走到结尾的时候,其实这就是开头。
循环链表和非循环链表其实创建的过程唯一不同的是,非循环链表的尾结点指向空(NULL),而循环链表的尾指针指向的是链表的开头。
通过将单链表的尾结点指向头结点的链表称之为循环单链表(Circular linkedlist)
一个完整的循环单链表如图: