每一个孔代表的是一个布尔表达式,也就是一个答案为『是』或者『否』的问题。举个例子,这些文档是关于某些天天气状况的,那么每个孔的对应如下问题:
是否下雨
气温是否大于30℃
气温是否小于0℃
……
以此类推,然后,对于每一个答案为『否』的孔,将其剪掉:

最后把所有文档用线串起来,有孔的穿孔,没孔的穿洞,就像这样(示意图并没有画全):

最后这所有文档将被40条线串起来。然后,当需要查找某个问题为『是』的文档,只需要将其对应的绳子给提起来即可(因为回答为否的洞已经被剪开,提绳子的时候会掉下去),这样绳子上挂着的就都是相关的文档了。同时,这个索引还支持逻辑或运算。利用布尔运算的定律,支持逻辑与运算也是非常简单的。
大名鼎鼎的bloom filter就是对这个原理的总结提炼。
由此可见,支持增删改查的数据库未必都有表,未必都是关系型数据。
关系型数据库为什么入选计算机科学与技术的基础课程?因为它“科学”,换句话说,理论发展得比较完善。尚处在发展中,有大量未知问题的领域不太适合作本科基础教学,那种感觉就像高中学物理和学化学的一样,物理把为数不多的几个定理和数据组合一下总能得到结果,而化学感觉是一堆『拍脑袋想出来的规则』加一堆『被疯狂打脸的例外』……这里不是我故意要『黑』一下化学,大神Matrix67也有同样的感觉:
之所以在高中时选择学文科,是因为他对化学“很不认同”。高一分专业考试时,他的化学不及格,为了进实验班,只好学了文科。“化学这门学科实在是太不科学了,缺乏内在美。”一提起化学,他总是不住地摇头。
感兴趣的可以看看这个帖子里化学大神们的讨论:为什么中学化学给人一种不严谨的感觉?
注意我这里并不是要否定化学的科学性,因为即便是物理在深入到尚未完善的领域之后依然是一对规则加一堆例外——二十世纪初当人们一度认为物理学已经完备的时候,天空飘来了两朵乌云,然后引起了物理理论的一场革命。我这里只是想用两个学科学习的直观感受来说明从关系型数据库入手对学生来说更容易。
另一方面,教学配套材料很多,对于学生入门和老师教学来说非常方便,可以让教学更关注于本质——数据库系统的构建思想。我以为,数据库原理课程的精髓,应当是数据库构建的过程,而数据库本身的使用反而是最不重要的一环。
我曾经在知乎上讨论过另一个问题:大学编程入门为什么不以C#作为首选?其实和这个问题有点类似。你说用C#来教操作系统我支不支持,如果有好的配套材料,比如用C#写好的教学操作系统,我当然支持。但是,现在绝大部分的操作系统底层无一例外是C写的,绝大部分操作系统课的课程作业也是C语言,工业界绝大部分系统级底层应用也是用C写的,而且操作系统课程的核心恰恰不是语言,而是架构的设计——既然如此,何必舍本逐末,舍近求远,把目光放在C还是C#上呢?
那么回到这个问题,同样的,学习数据库原理的目的是什么,是怎么使用吗?一部分目的是,学会了原理能够更好的使用;但是,另一个更重要的目的,是在现有的数据库解决方案不能满足需求的时候,如何利用在构建关系型数据库过程中积累的方法经验,开发在特定场景下更好的数据库应用。
先看看关系型数据库是什么——它是对一类数据库设计经验的总结和设计方法的抽象,以期得到一个通用的数据库的解决方法。
打个比方,小学奥数题鸡兔同笼问题:
有若干只鸡兔同在一个笼子里,从上面数,有35个头,从下面数,有94只脚。问笼中各有多少只鸡和兔?
小学的解法有很多种:
假设法
假设全是鸡:2×35=70(只)
鸡脚比总脚数少:94-70=24 (只)
兔子比鸡多的脚数:4-2=2(只)
兔子的只数:24÷2=12 (只)
鸡的只数:35-12=23(只)
假设全是兔子:4×35=140(只)
兔子脚比总数多:140-94=46(只)
兔子比鸡多的脚数:4-2=2(只)
鸡的只数:46÷2=23(只)
兔子的只数=35-23=12(只)
抬腿法一
假如让鸡抬起一只脚,兔子抬起2只脚,还有94÷2=47(只)脚。笼子里的兔就比鸡的脚数多1,这时,脚与头的总数之差47-35=12,就是兔子的只数。
抬腿法二、抬腿法三……
你看,同一个问题,张三有张三的解法,李四有李四的解法。于是聪明的王五在观察所有方法之后,做了一个总结,解决这个问题我们可以使用一元一次方程:
解:设兔有x只,则鸡有(35-x)只。
4x 2(35-x)=94
解得 x=12
又进一步,有人发现,牛吃草问题也可以用方程解,于是在这基础上发展了二元一次方程,甚至N元一次方程。进一步,当研究到更复杂的问题的时候,比如抛物线,行星轨道,发现一次方程不够用了,于是又进一步扩展出了高次方程……
于是,我们的代数系统渐渐发展,变成了如今这样庞大的体系,也足够应付相当一部分应用场景:小商小贩的价格计算、金融模型、天梯轨迹的预测……
数据库也是类似的发展轨迹。
@wivwiv
在回答里提到这样一个例子:
去年作为大三学生去旁听毕业答辩,某同学作品是一个安卓端的英汉词典,支支吾吾吞吞吐吐说不清他数据的存储方式,老师只好降低难度让他把 Apple 的中文改为 梨。
他一番摸索,工程下找到了一个 txt 文件,ctrl f 来把这个翻译对照改了。懂行的憋住笑,不懂行的觉得没毛病,答辩老师一致拍案叫绝,遂过。
不懂基本的数据库,你以后得工程要存数据是不是也这样?
其实,这个同学的英汉词典采用这样的存储方式并没有太大的不妥,这恰恰是数据库的某种意义上的基本形态——二维表,也就是关系数据库中的『关系』,应付这种场景足矣。
那么我们先来看看关系型数据库到底试图解决一个什么样的问题?ACID:
Atomicity:原子性
Consistency:一致性
Isolation:隔离性
Duration:持久性
这里我就不详细展开了,需要了解的去看课本。在这其中,『一致性』是重中之重。
为什么要学范式?在你困惑的那些概念中,各种所谓的『范式』很大程度上就是为一致性提供服务的。
就拿1NF(关系中的每个属性都不可再分)来说吧,乍看好像没什么用,但是上次我看到这个问题的讨论就忍俊不禁:如何劝说后端开发不要拿变量命名 JSON 的key值?
@max poon
的回答:
问问他,如果以后需要加多一个author属性,他准备如何拓展。
@Axetroy
回复:
然后后端一听, 这简单, 看我的
[{'书籍1':"500|作者1"},{'书籍2':"180|作者2"},{...},...]
你可以仔细思考一下,如果在创建表的时候不遵循1NF,查询的时候会导致什么样的后果?1NF又给我们查询带来了哪些方便?显然,其中一个好处就是,查询的时候不需要再对得到的内容进一步解析。
那么2NF、3NF乃至BCNF又是用来解决什么问题的呢?
@刘慰
老师的回答非常清晰和详细,可以参阅:解释一下关系数据库的第一第二第三范式?如果认真读完,你应该能够有一个清晰的认识,限于篇幅和时间,我在这里就不展开了。
为什么要学关系代数?简单来说,就是关系代数是对关系数据库查询所做的抽象。抽象的好处是减少人脑的负担,有了抽象之后,我们可以忽略掉工程上的细节,更清晰地看到某些问题的本质,从而从数学上做一些推理和优化:当一切都变成表达式之后,我们就可以利用数学性质做推理了,而不必去关心实现的细节——因为那都是抽象之后可以忽略的底层信息。
其实,从本质上来说,『关系代数』与『线性代数』和『布尔代数』并没有什么区别,如果你学过『抽象代数』的话应该会有更深的体会。
一个例子便是计算优化。线性代数是大学生的必修课程,在这里我就举一个简单的例子,线性代数中的矩阵乘法运算满足结合律与左右分配律。对于多个矩阵连乘的计算,使用不同的计算顺序会导致计算量千差万别。如果能按照计算量最小的矩阵乘法顺序进行计算,可以大大加速矩阵乘法的计算——这是一个经典的动态规划算法应用:0010算法笔记--【动态规划】矩阵连乘问题 - CSDN博客
同样的,在关系代数里,也有可以用类似的方法加速计算。比方说,『自然连接』,也就是SQL里的『natural join』操作也满足结合律,这样就大大方便了计算优化。如果你了解join的底层实现,不论是hash join,还是nested loop join,抑或是其他任何算法,一般来说,需要join的两个表行数越多,计算量越大。那么,越早做哪些让行数减少的join,之后的join的计算量就越小,而连续join的次数越多,这个差异就越大。
对于如下这个稍微复杂一点的SQL查询:
SELECT
people.name,
orgunits.longname,
people.email,
affiliations.starting,
count(DISTINCT subjects.code)
FROM
staff
JOIN people ON staff.id = people.id
JOIN affiliations ON affiliations.staff = people.id
JOIN staff_roles ON staff_roles.id = affiliations.role
JOIN orgunits ON orgunits.id = affiliations.orgunit
JOIN orgunit_types ON orgunits.utype = orgunit_types.id
JOIN course_staff ON course_staff.staff = staff.id
JOIN courses ON courses.id = course_staff.course
JOIN subjects ON subjects.id = courses.subject
WHERE
affiliations.isprimary = TRUE
AND staff_roles.name = 'Head of School'
AND affiliations.ending IS
AND orgunit_types.name = 'School'
AND course_staff.staff = people.id
GROUP BY
people.name,
orgunits.longname,
people.email,
affiliations.starting
HAVING
count(subjects.code) > 0
ORDER BY
people.name ASC;
调用explain命令来看看postgres内部是如何执行这个查询的,这就是所谓的query plan:
GroupAggregate (cost=634.26..634.32 rows=2 width=82)
Group Key: people.name, orgunits.longname, people.email, affiliations.starting
Filter: (count(subjects.code) > 0)
-> Sort (cost=634.26..634.27 rows=2 width=83)
Sort Key: people.name, orgunits.longname, people.email, affiliations.starting
-> Nested Loop (cost=28.48..634.25 rows=2 width=83)
-> Nested Loop (cost=28.19..633.53 rows=2 width=78)
-> Nested Loop (cost=27.91..633.21 rows=1 width=90)
-> Nested Loop (cost=27.61..632.84 rows=1 width=90)
-> Nested Loop (cost=27.32..301.62 rows=1 width=82)
-> Nested Loop (cost=27.03..300.80 rows=1 width=39)
Join Filter: (affiliations.role = staff_roles.id)
-> Seq Scan on staff_roles (cost=0.00..18.05 rows=1 width=4)
Filter: ((name)::text = 'Head of School'::text)
-> Hash Join (cost=27.03..271.74 rows=881 width=43)
Hash Cond: (affiliations.orgunit = orgunits.id)
-> Seq Scan on affiliations (cost=0.00..202.85 rows=8807 width=16)
Filter: (isprimary AND (ending IS ))
-> Hash (cost=26.22..26.22 rows=65 width=35)
-> Hash Join (cost=1.14..26.22 rows=65 width=35)
Hash Cond: (orgunits.utype = orgunit_types.id)
-> Seq Scan on orgunits (cost=0.00..17.48 rows=648 width=39)
-> Hash (cost=1.12..1.12 rows=1 width=4)
-> Seq Scan on orgunit_types (cost=0.00..1.12 rows=1 width=4)
Filter: ((name)::text = 'School'::text)
-> Index Scan using people_pkey on people (cost=0.29..0.82 rows=1 width=43)
Index Cond: (id = affiliations.staff)
-> Index Only Scan using course_staff_pkey on course_staff (cost=0.29..331.08 rows=14 width=8)
Index Cond: (staff = people.id)
-> Index Scan using courses_pkey on courses (cost=0.29..0.36 rows=1 width=8)
Index Cond: (id = course_staff.course)
-> Index Only Scan using staff_pkey on staff (cost=0.29..0.32 rows=1 width=4)
Index Cond: (id = people.id)
-> Index Scan using subjects_pkey on subjects (cost=0.29..0.36 rows=1 width=13)
Index Cond: (id = courses.subject)
简单解释一下,这里面第一行的GroupAggregate和后面行->后跟着的表示一个基本操作,基本上可以对应到关系代数中的各种运算,比如GroupAggregate就是聚集运算,Hash Join是Join的一种实现方式,等等;缩进代表的是这些操作的隶属关系。
看到了吧,这就是所谓隐藏在关系代数背后的细节——的一部分。跟原始的query比较一下,你会发现join的顺序已经发生了改变。括号内你可以看到每一个操作的cost,它的join是从cost最小的开始的(你可以理解为产生的行数最少),这就是利用关系运算的定律以及数据库本身的统计信息来计算的优化。当然了,这样的计算是粗糙的,有时候结果未必是最优的,具体可以看看这个例子:How a single PostgreSQL config change improved slow query performance by 50x,就是因为数据库的默认设置是机械硬盘,而使用的是固态硬盘,导致cost的计算出现了偏差。
更多采用关系代数对数据查询进行优化的例子可以看这里,我也就不展开了:Relational algebra
关系型数据库的不足前面说到,我们目前的代数体系已经相当庞大,涵盖了我们生活的方方面面。但是寄希望于在代数体系内解决一切问题是不可能的:
哥德尔的不完备性定理证明了数学是一个未完结的学科,永远有需要我们以人的头脑从系统之外去用我们独有的直觉发现的东西。
高度发展的代数系统尚且如此,更何况才发展不到百年的数据库系统呢?关系代数作为关系型数据库的理论基础,它的局限性也是关系型数据库的局限性——正如同停机问题指出了图灵机的局限性一样。由于我数理逻辑学得并不好,这里不敢不懂装懂,理论方面没法解释,只能从一些别的角度来探讨了。
理论虽然简单优雅,可是实践起来逃不开软硬件的限制。
一致性带来的性能问题
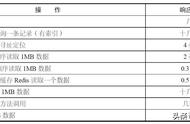
鉴于一致性的种类很多,这里就说强一致性。为了提升数据库的性能,往往采用多线程进行实现。而为了保证强一致性,在读写操作里面就需要加锁。当然,最简单的方法是给整个数据库加一个互斥锁——这样正确性保证了,性能却不行了。于是就有考虑更细粒度的加锁。数据库中B 树如此重要,除了读写上有优势之外,更重要的原因是它加锁很方便——当然了,方便只是相对而言的,真正实现起来非常繁琐——如果你已经上了系统课就应该了解,一旦牵涉到锁,问题就多了:死锁、活锁、饥饿……这些都是需要考虑的问题,当这个问题被抽象出来之后,就有了下面这张表:

我们需要小心翼翼地去使用锁,才能够避免上述问题的发生——光这一个话题,就有好多论文了。而近几年微软弄出了一套叫做BW-树的结构,使用原子操作和特殊的维护方法避免掉了锁的使用:The Bw-Tree: A B-tree for New Hardware Platforms - Microsoft Research
同时,一致性的要求还会引起分布式系统之间的同步问题,这个话题也比较广,在这里也就不展开了。
连接的开销
关系型数据库的核心就是连接,然而join本身是一个比较重的操作。如果你对数据库内部两个表怎么join不是很了解的话,你可以思考思考一下你会怎么去实现?
其实原理很简单,最最基本的就是,如果有索引可以用hash join,没有index就只能两层for循环对两个表进行遍历了——当然,为了提高缓存命中率,有一个常见的优化技巧是分块for循环,但本质上还是两层for循环。
然而,由于关系型数据库本身的存储和索引方式,join操作的开销依然非常巨大。
有一种非常常见的情况就是社交网络的N步邻居查询。假设我们有一个表people (id int, name text),还有一个表friend (from int, to int, attr1 type1, att2 type2, ...),假设我们要查3步邻居怎么办?得这么做:
SELECT DISTINCT friend_3.id
FROM people
JOIN friend friend_1 ON friend_1.from = people.id
JOIN friend friend_2 ON friend_2.from = friend_1.to
JOIN friend friend_3 ON friend_3.from = friend_2.to
WHERE ...;
当然,对于这种查询,经常会有一些每一步查询计算量都是指数级增长,缓存命中率直线下降。更致命的是,它只能单点查询,如果想同时对多个点查询,只能分别执行多个SQL语句,加剧锁带来的资源消耗和性能下降。另一方面,要写递归查询、不定长度的查询非常困难。
所以,在反洗钱、电话诈骗等深度链接分析的应用领域,图数据库开始崛起——我说的是真·图数据库,那种给关系型数据库套壳的不算。
关系模型往往不是最自然的抽象
之前说了,为了方便查询的实现和对查询进行优化,加入了各种范式。但是这些范式往往限制了我们用直接的方法去建立模型。比如说,一个常用的数据库测试数据集是TPC-H,先来看看它的表结构: