今天我们来讨论微服务架构中的自我恢复能力。通常情况下,服务间会通过同步或异步的方式进行通信。我们假定把一个庞大的系统分解成一个个的小块能将各个服务解耦。管理服务内部的通信可能有点困难了。你可能听说过这两个著名的概念:熔断和重试。
熔断器

01
想象一个简单的场景:用户发出的请求访问服务 A 随后访问另一个服务 B。我们可以称 B 是 A 的依赖服务或下游服务。到服务 B 的请求在到达各个实例前会先通过负载均衡器。
后端服务发生系统错误的原因有很多,例如慢查询、network blip 和内存争用。在这种场景下,如果返回 A 的 response 是 timeout 和 server error,我们的用户会再试一次。在混乱的局面中我们怎样来保护下游服务呢?

02
熔断器可以让我们对失败率和资源有更好的控制。熔断器的设计思路是不等待 TCP 的连接 timeout 快速且优雅地处理 error。这种 fail fast 机制会保护下游的那一层。这种机制最重要的部分就是立刻向调用方返回 response。没有被 pending request 填充的线程池,没有 timeout,而且极有可能烦人的调用链中断者会更少。此外,下游服务也有了充足的时间来恢复服务能力。完全杜绝错误很难,但是减小失败的影响范围是有可能的。

03
通过 hystrix 熔断器,我们可以采用降级方案,对上游返回降级后的结果。例如,服务 B 可以访问一个备份服务或 cache,不再访问原来的服务 C。引入这种降级方案需要集成测试,因为我们在 happy path(译注:所谓 happy path,即测试方法的默认场景,没有异常和错误信息。具体可参见 wikipedia)可能不会遇到这种网络模式。
状态

04
熔断器有三个主要的状态:
- Closed:让所有请求都通过的默认状态。在阈值下的请求不管成功还是失败,熔断器的状态都不会改变。可能出现的错误是 Max Concurrency(最大并发数)和 Timeout(超时)。
- open:所有的请求都会返回 Circuit Open 错误并被标记为失败。这是一种不等待处理结束的 timeout 时间的 fail-fast 机制。
- Half Open:周期性地向下游服务发出请求,检查它是否已恢复。如果下游服务已恢复,熔断器切换到 Closed 状态,否则熔断器保持 Open 状态。
熔断器原理
控制熔断的设置共有 5 个主要参数。
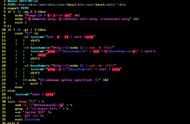
//CommandConfigisusedtotunecircuitsettingsatruntime
typeCommandConfigstruct{
Timeoutint`json:"timeout"`
MaxConcurrentRequestsint`json:"max_concurrent_requests"`
RequestVolumeThresholdint`json:"request_volume_threshold"`
SleepWindowint`json:"sleep_window"`
ErrorPercentThresholdint`json:"error_percent_threshold"`
}
查看源码
可以通过根据两个服务的 SLA( Service Level Agreement,服务级别协议)来定出阈值。如果在测试时把依赖的其他服务也涉及到了,这些值会得到很好的调整。
一个好的熔断器的名字应该能精确指出哪个服务连接出了问题。实际上,请求一个服务时可能会有很多个 API endpoint。每一个 endpoint 都应该有一个对应的熔断器。
生产上的熔断器
熔断器通常被放在聚合点上。尽管熔断器提供了一种 fail-fast 机制,但我们仍然需要确保可选的降级方案可行。如果我们因为假定需要降级方案的场景出现的可能性很小就不去测试它,那(之前的努力)就是白费力气了。即使在最简单的演练中,我们也要确保阈值是有意义的。以我的个人经验,把参数配置在 log 中 print 出来对于 debug 很有帮助。
Demo
这段实例代码用的是 hystrix-go 库,hystrix Netflix 库在 Golang 的实现。
packagemain
import(
"errors"
"fmt"
"log"
"net/http"
"os"
"github.com/afex/hystrix-go/hystrix"
)
constcommandName="producer_api"
funcmain(){
hystrix.ConfigureCommand(commandName,hystrix.CommandConfig{
Timeout:500,
MaxConcurrentRequests:100,
ErrorPercentThreshold:50,
RequestVolumeThreshold:3,
SleepWindow:1000,
})
http.HandleFunc("/",logger(handle))
log.Println("listeningon:8080")
http.ListenAndServe(":8080",nil)
}
funchandle(whttp.ResponseWriter,r*http.Request){
output:=make(chanbool,1)
errors:=hystrix.Go(commandName,func()error{
//talktootherservices
err:=callChargeProducerAPI()
//err:=callWithRetryV1()
iferr==nil{
output<-true
}
returnerr
},nil)
select{
caseout:=<-output:
//success
log.Printf("success%v",out)
caseerr:=<-errors:
//failure
log.Printf("failed%s",err)
}
}
//loggerisHandlerwrapperfunctionforlogging
funclogger(fnhttp.HandlerFunc)http.HandlerFunc{
returnfunc(whttp.ResponseWriter,r*http.Request){
log.Println(r.URL.Path,r.Method)
fn(w,r)
}
}
funccallChargeProducerAPI()error{
fmt.Println(os.Getenv("server_ERROR"))
ifos.Getenv("SERVER_ERROR")=="1"{
returnerrors.New("503error")
}
returnnil
}
demo 中分别测试了请求调用链 closed 和 open 两种情况:
/*Experiment1:successpath*/
//server
gorunmain.go
//client
foriin$(seq10);docurl-x''localhost:8080;done
/*Experiment2:circuitopen*/
//server
SERVER_ERROR=1Gorunmain.go
//client
foriin$(seq10);docurl-x''localhost:8080;done
查看源码
重试问题
在上面的熔断器模式中,如果服务 B 缩容,会发生什么?大量已经从 A 发出的请求会返回 5xx error。可能会触发熔断器切换到 open 的错误报警。因此我们需要重试以防间歇性的 network hiccup 发生。
一段简单的重试代码示例:
packagemain
funccallWithRetryV1()(errerror){
forindex:=0;index<3;index {
//callproducerAPI
err:=callChargeProducerAPI()
iferr!=nil{
returnerr
}
}
//addingbackoff
//addingjitter
returnnil
}
查看源码
重试模式
为了实现乐观锁,我们可以为不同的服务配置不同的重试次数。因为立即重试会对下游服务产生爆发性的请求,所以不能用立即重试。加一个 backoff 时间可以缓解下游服务的压力。一些其他的模式会用一个随机的 backoff 时间(或在等待时加 jitter)。
一起来看下列算法:
- Exponential: bash * 2attemp
- Full Jitter: sleep = rand(0, base * 2attempt)
- Equal Jitter: temp = base * 2attemp; sleep = temp/2 rand(0, temp/2)
- De-corredlated Jitter: sleep = rand(base, sleep*3)
【译注】关于这几个算法,可以参考这篇文章 。Full Jitter、 Equal Jitter、 De-corredlated 等都是原作者自己定义的名词。

05
客户端的数量与服务端的总负载和处理完成时间是有关联的。为了确定什么样的重试模式最适合你的系统,在客户端数量增加时很有必要运行基准测试。详细的实验过程可以在这篇文章中看到。我建议的算法是 de-corredlated Jitter 和 full jitter 选择其中一个。
两者结合

Example configuration of both tools
熔断器被广泛用在无状态线上事务系统中,尤其是在聚合点上。重试应该用于调度作业或不被 timeout 约束的 worker。经过深思熟虑后我们可以同时用熔断器和重试。在大型系统中,service mesh 是一种能更精确地编排不同配置的理想架构。
参考文章
- https://github.com/afex/hystrix-go/
- https://github.com/eapache/go-resiliency
- https://github.com/Netflix/Hystrix/wiki
- https://www.awsarchitectureblog.com/2015/03/backoff.html
- https://dzone.com/articles/go-microservices-part-11-hystrix-and-resilience
via: https://medium.com/@trongdan_tran/circuit-breaker-and-retry-64830e71d0f6
作者:Dan Tran译者:lxbwolf校对:polaris1119
本文由 GCTT 原创编译,Go 中文网 荣誉推出
喜欢本文的朋友,欢迎关注“Go语言中文网”
,