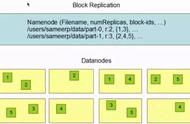
您也可以使用HUE的“上传”按钮,直接从您的计算机上传文件到HDFS。
YARN
YARN (另一个资源协商器)负责管理Hadoop集群上的资源,并允许运行各种分布式应用程序来处理存储在HDFS上的数据。
YARN类似于HDFS,遵循主从设计,ResourceManager进程充当主程序,多个NodeManager充当工作人员。它们的职责如下:
ResourceManager
跟踪集群中每个服务器上的LiveNodeManager和可用计算资源的数量。
为应用程序分配可用资源。
监视Hadoop集群上所有应用程序的执行情况。
NodeManager
管理Hadoop集群中单个节点上的计算资源(RAM和CPU)。
运行各种应用程序的任务,并强制它们在限定的计算资源范围之内。
YARN以资源容器的形式将集群资源分配给各种应用程序,这些资源容器代表RAM数量和CPU核数的组合。
在YARN集群上执行的每个应用程序都有自己的ApplicationMaster进程。当应用程序被安排在集群上并协调此应用程序中所有任务的执行时,此过程就开始了。

图3展示了YARN进程在4节点集群上运行两个应用程序的协作情况,共计产生7个任务。
HADOOP = HDFS YARN
在同一个集群上运行的HDFS和YARN为我们提供了一个存储和处理大型数据集的强大平台。
DataNode和NodeManager进程配置在相同的节点上,以启用本地数据。这种设计允许在存储数据的机器上执行计算,从而将通过网络发送大量数据的必要性降到最低,使得执行时间更快。

YARN 应用程序
YARN仅仅是一个资源管理器,它知道如何将分布式计算资源分配给运行在Hadoop集群上的各种应用程序。换句话说,YARN本身不提供任何处理逻辑来分析HDFS中的数据。因此,各种处理框架必须与YARN集成(通过提供ApplicationMaster实现),以便在Hadoop集群上运行,并处理来自HDFS的数据。
下面介绍几个最流行的分布式计算框架,这些框架都可以在由YARN驱动的Hadoop集群上运行。
MapReduce:Hadoop的最传统和古老的处理框架,它将计算表示为一系列映射和归约的任务。它目前正在被更快的引擎,如Spark或Flink所取代。
Apache Spark:用于处理大规模数据的快速通用引擎,它通过在内存中缓存数据来优化计算(下文将详细介绍)。
Apache Flink:一个高吞吐量、低延迟的批处理和流处理引擎。它以其强大的实时处理大数据流的能力脱颖而出。下面这篇综述文章介绍了Spark和Flink之间的区别:dzone.com/ports/apache-Hadoop-vs-apache-smash
Apache Tez:一个旨在加速使用Hive执行SQL查询的引擎。它可在Hortonworks数据平台上使用,在该平台中,它将MapReduce替换为Hive.k的执行引擎。
监控YARN应用程序
使用ResourceManager WebUI可以跟踪运行在Hadoop集群上的所有应用程序的执行情况,默认情况下,它在端口8088。

每个应用程序都可以读取大量重要信息。
使用ResourceManager WebUI,可以检查RAM总数、可用于处理的CPU核数量以及
当前Hadoop集群负载。查看页面顶部的“集群度量”。
单击"ID"列中的条目,可以获得有关所选应用程序执行的更详细的度量和统计数据。
用HADOOP处理数据
有许多框架可以简化在Hadoop上实现分布式应用程序的过程。在本节中,我们将重点介绍最流行的几种:HIVE和Spark。
HIVE
Hive允许使用熟悉的SQL语言处理HDFS上的数据。
在使用Hive时,HDFS中的数据集表示为具有行和列的表。因此,对于那些已经了解SQL并有使用关系数据库经验的人来说,Hive很容易学习。
Hive不是独立的执行引擎。每个Hive查询被翻译成MapReduce,Tez或Spark代码,随后在Hadoop集群中得以执行。
HIVE 例子
让我们处理一个关于用户在一段时间里听的歌曲的数据集。输入数据由一个名为Song s.tsv的tab分隔文件组成:
Creep" Radiohead piotr 2017-07-20 Desert Rose" Sting adam 2017-07-14 Desert Rose" Sting piotr 2017-06-10 Karma Police" Radiohead adam 2017-07-23 Everybody" Madonna piotr 2017-07-01 Stupid Car" Radiohead adam 2017-07-18 All This Time" Sting adam 2017-07-13
现在用Hive寻找2017年7月份两位最受欢迎的艺术家。
将Song s.txt文件上传HDFS。您可以在HUE中的“File Browser”帮助下完成此操作,也可以使用命令行工具键入以下命令:
# hdfs dfs -mkdir /user/training/songs
# hdfs dfs -put songs.txt /user/training/songs
使用Beeline客户端进入Hive。您必须向HiveServer 2提供一个地址,该进程允许远程客户端(如Beeline)执行Hive查询和检索结果。
# beeline
beeline> !connect jdbc:hive2://localhost:10000 <user><password>
在Hive中创建一个指向HDFS数据的表(请注意,我们需要指定文件的分隔符和位置,以便Hive可以将原始数据表示为表):