三、基本关系查看
1.散点图
利用SPSSAU“可视化”→“散点图”做数据的散点图,观察因变量与自变量之间是否具有线性特点。

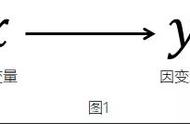
从上图中可以看出,创业可能性和教育水平、社会资源以及科技发展均存在线性关系,其中Y轴为因变量创业可能性,X轴为自变量。接下来查看数据的相关性。
2.相关性分析
相关分析是研究有没有关系,回归分析是研究影响关系。明显地,相关分析是基础,然后再进行回归分析。首先需要知道有没有相关关系;有了相关关系,才可能有回归影响关系;如果没有相关关系,是不应该有回归影响关系的。

从上表可知,利用相关分析去研究创业可能性和社会资源,
教育水平,
科技发展共3项之间的相关关系,使用Pearson相关系数去表示相关关系的强弱情况。具体分析可知:
创业可能性与教育水平共1项之间全部均呈现出显著性,相关系数值分别是0.232,全部均大于0,意味着创业可能性与教育水平共1项之间有着正相关关系。同时,创业可能性与社会资源,
科技发展共2项之间并不会呈现出显著性,相关系数值接近于0,说明创业可能性与社会资源,
科技发展共2项之间并没有相关关系。相关与回归并没有百分之百的联系,从模型完整性来讲,对于不相关的变量也可以纳入模型进行分析但是如果没有相关关系,是不应该有回归影响关系的。
四、线性回归结果
基本关系查看后,我们切入正题利用SPSSAU通用方法的线性回归进行回归分析,接下来对回归结果进行说明,其中包括模型效果(因为主要说影响关系大小,避免重复省略该步骤)以及模型结果两大部分。具体如下:

另外,模型中包括性别、年龄控制变量,控制变量指可能干扰模型的项,比如年龄,学历等基础信息。从软件角度来看,并没有“控制变量”这样的名词。“控制变量”就是自变量,所以直接放入“自变量X”框中就好。 另外,控制变量一般是定类数据,理论上控制变量需要作“虚拟(哑)变量”设置,但实际研究中很少这样做而是直接放入模型中,可能原因是“控制变量”并非核心研究项,所以不用考虑太过复杂。
模型结果
回归的中间过程包括F检验、拟合优度、多重共线性以及自相关性,这些都是在分析前需要进行观测与分析的,接下来将从模型公式、分析结果、影响关系大小以及其它方面进行对模型结果的阐述。
(1)模型公式