对于数据科学的艺术,统计学可以说是一个强大的工具。从高层次的角度来看,统计是利用数学对数据进行技术分析。一个基本的可视化,如条形图,可以给你提供一些高级的信息,但是通过统计学,我们可以以一种更加以信息驱动和更有针对性的方式来操作数据。所用到的数学方法能帮助我们对数据形成具体的结论,而不是去靠猜测。
通过使用统计学,我们可以更深入、更细致地了解我们的数据到底是如何构造的,并基于这种结构,我们如何最佳地应用其他数据科学技术来获取更多的信息。现在,我们来看看数据科学家们需要知道的5个基本统计概念,以及如何才能最有效地应用它们!
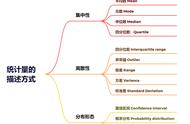
统计特征统计特征可能是数据科学中最常用的统计概念。它通常是你在探索数据集时应用的第一种统计技术,包括偏差(bias),方差,均值,中位数,百分位数等等。在代码中理解和实现都非常容易!

箱形图(也称为盒须图)
中值的线是数据的中位数(median )。由于中位数对离群值的鲁棒性更强,因此中位数要比均值更常用。第一个四分位数(first quartile)基本上是第25个百分位,即数据中25%的点低于该值。第三个四分位数(third quartile)是第75百分位,即数据中75%的点低于该值。最小值和最大值表示数据范围的上端和下端。
箱形图完美地说明了我们可以用基本统计特征做什么:
- 当箱形图很短时,它意味着大部分数据点都相似,因为大多数值在在很小的范围内
- 当箱形图很高时,它意味着大部分数据点都非常不同,因为这些值分布在很广的范围内
- 如果中值接近底部,那么我们知道大多数数据具有较低的值。如果中值接近顶部,那么我们知道大多数数据具有更高的值。基本上,如果中值的线不在框的中间,则表明数据偏斜。
- 是否有长尾?这意味着数据具有较高的标准偏差和方差,即数值分散且变化很大。如果盒子的一侧有须,而另一侧没有,那么你的数据可能只在一个方向上变化很大。
所有这些信息来自一些易于计算的简单统计特征!只要你需要快速而翔实的数据视图,请尝试这些。
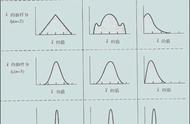
概率分布我们可以将概率定义为某个事件发生的几率。在数据科学中,通常被量化在0到1之间,0表示我们确信这不会发生,1表示我们确信它会发生。另外,概率分布是表示实验中所有可能值概率的函数。如下图: