为每一列设置特定的数据类型
对于许多初级数据科学家来说,数据类型并非关注的重点。但是一旦开始处理非常庞大的数据集,数据类型就变得非常重要。
通常的做法是读取数据帧,然后根据需要转换某一列的数据类型。但对于一个大的数据集来说,内存空间必须纳入考虑范围。
CSV文件中,浮点数等列占用的空间比实际需要得更多。例如,如果下载一个用于预测股价的数据集,这些股价可能被保存为32位浮点数!
但真的需要32位浮点数吗?很多时候,股票是以小数点后两位的定价买进的。即使要做到更加精确,16位浮点数也足够了。
因此,相比于在数据集中读取列的原始数据类型,在pandas读取列时,设定所希望的数据类型将更加有效。因为这样占用的内存永远也不会超过实际需求量。
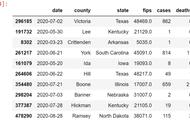
使用read_csv() 函数中的dtype参数可以轻松做到这一点。方法是指定一个词典,其中每个键都是数据集中的一列,每个值都是通过使用该键而希望获得的数据类型。
以下是pandas中的一个例子:

今天的教程就到这里,希望这三个方法能有效节约时间、节省内存!

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
,