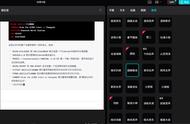
从YouTube下载视频的字幕格式是VTT的。要把VTT字幕文件转换成SRT或LRC格式,可以使用Python的webvtt库。
安装命令: pip install webvtt-py
WebVTT字幕格式与SRT字幕格式主要区别在于时间格式的区分。
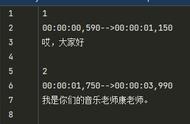
下面是一个WebVTT格式的字幕文件
00:00:20.000 --> 00:00:24.400
En réponse à l'augmentation dramatique
de la criminalité dans certains quartiers,
对应的SRT字幕格式则为
00:00:20,000 --> 00:00:24,400
En réponse à l'augmentation dramatique
de la criminalité dans certains quartiers,
安装完成后,在ChatGPT对话框中输入提示词:
你是一个Python编程专家,现在要完成一个将VTT格式的字幕文件转换成SRT格式和LRC的字幕文件,具体步骤如下:
打开文件夹:D:\lexfridman-podcast\vtt
读取文件夹中的vtt后缀文件,然后转换成SRT格式和LRC格式;
注意:每一步都要输出相关信息

ChatGPT给出的源代码:
import os
import webvtt
from datetime import datetime
def convert_vtt_to_srt(vtt_filename, srt_filename):
print(f"正在将 {vtt_filename} 转换为 {srt_filename}")
vtt = webvtt.read(vtt_filename)
with open(srt_filename, 'w', encoding='utf-8') as f:
for i, caption in enumerate(vtt):
f.write(str(i 1) '\n')
f.write(caption.start.replace('.', ',') ' --> ' caption.end.replace('.', ',') '\n')
f.write(caption.text '\n\n')
def convert_vtt_to_lrc(vtt_filename, lrc_filename):
print(f"正在将 {vtt_filename} 转换为 {lrc_filename}")
vtt = webvtt.read(vtt_filename)
with open(lrc_filename, 'w', encoding='utf-8') as f:
for caption in vtt:
start = datetime.strptime(caption.start, '%H:%M:%S.%f')
f.write(f"[{start.minute}:{start.second:02}.{start.microsecond//10000}]{caption.text}\n")
# 打开文件夹
folder = 'D:\\lexfridman-podcast\\vtt'
print(f"打开文件夹: {folder}")
# 读取文件夹中的vtt后缀文件
for filename in os.listdir(folder):
if filename.endswith('.vtt'):
base_filename = os.path.splitext(filename)[0]
vtt_filename = os.path.join(folder, filename)
srt_filename = os.path.join(folder, base_filename '.srt')
lrc_filename = os.path.join(folder, base_filename '.lrc')
convert_vtt_to_srt(vtt_filename, srt_filename)
convert_vtt_to_lrc(vtt_filename, lrc_filename)

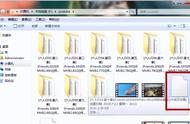
运行程序,全部成功转换: