- 一、前期准备:
编译环境:Python 3.4
Python库:requests、re、urllib、BeautifulSoup
- 二、实现分析:
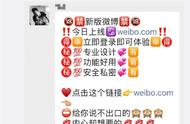
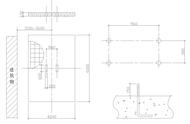
尝试爬虫登陆网站时,会涉及到很多Javascript、验证码、cookies等很多的问题,为了避免太麻烦的登陆方式,我建议大家访问对应网站的移动版。比如访问新浪微博的移动版: http://weibo.cn ,登陆网址为http://login.weibo.cn/login/,登陆界面为:

登陆界面比较简单,不涉及验证码和Javascript处理的问题。
分析网页源码,登陆主要需要填写一个表格的数据,表单数据名分别为: 'tryCount'、'submit'、'vk'、'password_7659'、'backURL'、'remember'、'mobile'、'backTitle',这其中'password_7659'和'mobile'需要自己填写对应的密码和账户名,其余的直接提取原网页的数据即可。
这里,新浪对输入元素名做了处理,每次访问得到的password元素名都不相同,连接了一个四位的随机数字,所以提取password时需要用正则匹配出来。
登陆后需要保存cookie,我这里使用的request库的session模块,可以维持一个长时间的登陆状态。
- 三、源码
此源码实践时,请填入自己的账号密码。
- #!/usr/bin/python3
- import requests
- from bs4 import BeautifulSoup
- from urllib.request import urlopen
- import re
- #头信息,可以伪装为浏览器访问
- myHeaders = {}
- myHeaders["User-Agent"] ="Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:42.0) Gecko/20100101Firefox/42.0"
- myHeaders["Accept"] ="text/html,application/xhtml xml,application/xml;q=0.9,*/*;q=0.8"
- #登陆网址
- login_url ="http://login.weibo.cn/login/"
- print("====> The login_url: " login_url)
- print("====> Visit login_url...")
- login_reponse =requests.get(login_url,headers = myHeaders)
- #转化为BeautifulSoup对象
- bsObj = BeautifulSoup(login_reponse.text,"lxml")
- #提取出表单中的post网址
- action_url =bsObj.find("form").attrs["action"]
- action_url = login_url action_url
- print("====> The action_url: " action_url)
- print("====> Visit action_url...")
- #提取表单中的元素散列
- submit_dict = {}
- input_values = bsObj.find("form").findAll("input")
- for in_value in input_values:
- #name值作为主键,value作为值
- if"name" in in_value.attrs:
- if"value" in in_value.attrs:
- submit_dict[in_value.attrs["name"]]= in_value.attrs["value"]
- else:
- submit_dict[in_value.attrs["name"]]= ""
- #对于随机的password元素名,需要用正则提取
- ifre.match(r"password.*",in_value.attrs["name"]):
- #这里填入自己的密码
- submit_dict[in_value.attrs["name"]]= "************"
- ifin_value.attrs["name"] == "remember":
- submit_dict[in_value.attrs["name"]]= "on"
- ifin_value.attrs["name"] == "mobile":
- #这里填入自己的账号
- submit_dict[in_value.attrs["name"]]= "*************"
- session = requests.Session()
- s = session.post(action_url,params =submit_dict,headers = myHeaders)
- print("Login Success")
- #输出登陆成功后微博主页的内容
- print(s.text)
- #我们这里尝试发一条微博
- s =session.get("http://weibo.cn/")
- submit_url =BeautifulSoup(s.text,"lxml").find("form",action =re.compile("/mblog/sendmblog\?st=.*")).attrs["action"]
- weibo_content ={"rl":"0"}
- weibo_content["content"] = "微博测试~"
- s = session.post("http://weibo.cn/" submit_url,params= weibo_content,headers = myHeaders)