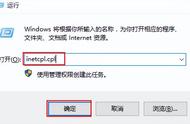
我们在使用浏览器的时候,浏览器会提供前进和后退功能。点击后退按钮时,能跳转到前一个浏览过的网页上。再点击前进按钮时,又能回到点击后退时的网页上。那这个功能是怎么实现的呢?
我们把这个业务功能问题转换成技术问题,实现浏览器的前进、后退功能,其实就是历史访问网页的存储和访问问题。例如,用户访问过的网页存在哪里?以什么样的顺序存储这些历史网页?当点击前进或后退时,又应该以什么样的算法计算出应该显示的历史网页?解决了这些问题,浏览器的前进和后退问题自然就解决了。
我们以一个实际的例子来描述我们的思路:一个用户访问了一个网站的主页A,然后通过主页A访问了新的页面B,浏览完页面B后又从页面B访问了一个新的页面C,浏览完页面C后又从页面C访问了一个新的页面D,然后用户想重新浏览页面B,因此从页面D连续两次点击了后退按钮跳转到了页面B,浏览完页面B后,又点击了前进按钮到页面C。重新浏览完页面C后,从页面C访问了一个新的页面E,又从页面E访问了一个新的页面F,最后从页面F连续两次点击了后退按钮后退到了页面C。
有了这样一个案例,我们再来通过代码实现用户操作的每一步:
首先一个用户访问了一个网站的主页A,然后通过主页A访问了新的页面B,这个时候我们就要考虑用户浏览过的页面A要存放在什么地方?因此我们新建一个栈1,用来存放用户浏览过的页面,此时栈1内的数据如下:

然后用户浏览完页面B后又从页面B访问了一个新的页面C,浏览完页面C后又从页面C访问了一个新的页面D,此时我们将用户浏览过历史页面依次放入栈1中,如下:

然后用户想重新浏览页面B,因此从页面D连续两次点击了后退按钮跳转到了页面B,这步操作用户点击了后退按钮,但是已经浏览过的D页面和C页面我们也不能直接丢弃,因此我们需要新建一个栈2,来存放因为点击了后退按钮而需要存储的页面D和页面C,如下:

然后用户浏览完页面B后,又点击了前进按钮到页面C。因为页面C存储在栈2中,因此用户点击前进按钮时,我们将栈2中的栈顶元素出栈,而页面B作为用户浏览过的历史页面压入栈1中,如下: