1. SQLite 视图(View)
2. SQLite 触发器(Trigger)
3. SQLite 索引(Index)
3.1 单列索引
3.2 唯一索引
3.3 组合索引
3.4 隐式索引
3.5 什么情况下要避免使用索引?
4. SQLite 事务(Transaction)
4.1 事务的属性( ACID)
4.2 事务控制
5. SQLite 约束
6. SQLite 子查询
6.1 SELECT 子查询使用
6.2 INSERT 子查询使用
6.3 UPDATE 子查询使用
6.4 DELETE 子查询使用
1. SQLite 视图(View)
视图(View)只不过是通过相关的名称存储在数据库中的一个 SQLite 语句。视图(View)实际上是一个以预定义的 SQLite 查询形式存在的表的组合。
视图(View)可以包含一个表的所有行或从一个或多个表选定行。视图(View)可以从一个或多个表创建,这取决于要创建视图的 SQLite 查询。
视图(View)是一种虚表,允许用户实现以下几点:
- 用户或用户组查找结构数据的方式更自然或直观。
- 限制数据访问,用户只能看到有限的数据,而不是完整的表。
- 汇总各种表中的数据,用于生成报告。
SQLite 视图是只读的,因此可能无法在视图上执行 DELETE、INSERT 或 UPDATE 语句。但是可以在视图上创建一个触发器,当尝试 DELETE、INSERT 或 UPDATE 视图时触发,需要做的动作在触发器内容中定义。
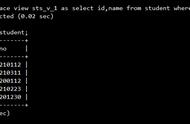
1.1 创建视图SQLite 的视图是使用 CREATE VIEW 语句创建的。SQLite 视图可以从一个单一的表、多个表或其他视图创建。
CREATE VIEW 的基本语法如下:
CREATE [TEMP | TEMPORARY] VIEW view_name AS
SELECT column1, column2.....
FROM table_name
WHERE [condition];
您可以在 SELECT 语句中包含多个表,这与在正常的 SQL SELECT 查询中的方式非常相似。如果使用了可选的 TEMP 或 TEMPORARY 关键字,则将在临时数据库中创建视图。
1.2 删除视图要删除视图,只需使用带有 view_name 的 DROP VIEW 语句。DROP VIEW 的基本语法如下:
sqlite> DROP VIEW view_name;
下面的命令将删除我们在前面创建的 COMPANY_VIEW 视图:
sqlite> DROP VIEW COMPANY_VIEW;
2. SQLite 触发器(Trigger)
SQLite 触发器(Trigger)是数据库的回调函数,它会在指定的数据库事件发生时自动执行/调用。以下是关于 SQLite 的触发器(Trigger)的要点:
- SQLite 的触发器(Trigger)可以指定在特定的数据库表发生 DELETE、INSERT 或 UPDATE 时触发,或在一个或多个指定表的列发生更新时触发。
- SQLite 只支持 FOR EACH ROW 触发器(Trigger),没有 FOR EACH STATEMENT 触发器(Trigger)。因此,明确指定 FOR EACH ROW 是可选的。
- WHEN 子句和触发器(Trigger)动作可能访问使用表单 NEW.column-name 和 OLD.column-name 的引用插入、删除或更新的行元素,其中 column-name 是从与触发器关联的表的列的名称。
- 如果提供 WHEN 子句,则只针对 WHEN 子句为真的指定行执行 SQL 语句。如果没有提供 WHEN 子句,则针对所有行执行 SQL 语句。
- BEFORE 或 AFTER 关键字决定何时执行触发器动作,决定是在关联行的插入、修改或删除之前或者之后执行触发器动作。
- 当触发器相关联的表删除时,自动删除触发器(Trigger)。
- 要修改的表必须存在于同一数据库中,作为触发器被附加的表或视图,且必须只使用 tablename,而不是 database.tablename。
- 一个特殊的 SQL 函数 RAISE() 可用于触发器程序内抛出异常。
语法
创建 触发器(Trigger) 的基本语法如下:
CREATE TRIGGER trigger_name [BEFORE|AFTER] event_name
ON table_name
BEGIN
-- Trigger logic goes here....
END;
在这里,event_name 可以是在所提到的表 table_name 上的 INSERT、DELETE 和 UPDATE 数据库操作。您可以在表名后选择指定 FOR EACH ROW。
以下是在 UPDATE 操作上在表的一个或多个指定列上创建触发器(Trigger)的语法:
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name
ON table_name
BEGIN
-- Trigger logic goes here....
END;
3. SQLite 索引(Index)索引(Index)是一种特殊的查找表,数据库搜索引擎用来加快数据检索。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书后边的索引是非常相似的。
例如,如果您想在一本讨论某个话题的书中引用所有页面,您首先需要指向索引,索引按字母顺序列出了所有主题,然后指向一个或多个特定的页码。
索引有助于加快 SELECT 查询和 WHERE 子句,但它会减慢使用 UPDATE 和 INSERT 语句时的数据输入。索引可以创建或删除,但不会影响数据。
使用 CREATE INDEX 语句创建索引,它允许命名索引,指定表及要索引的一列或多列,并指示索引是升序排列还是降序排列。
索引也可以是唯一的,与 UNIQUE 约束类似,在列上或列组合上防止重复条目。
CREATE INDEX 命令
CREATE INDEX 的基本语法如下:
CREATE INDEX index_name ON table_name;
3.1 单列索引单列索引是一个只基于表的一个列上创建的索引。基本语法如下:
CREATE INDEX index_name
ON table_name (column_name);
3.3 唯一索引使用唯一索引不仅是为了性能,同时也为了数据的完整性。唯一索引不允许任何重复的值插入到表中。基本语法如下:
CREATE UNIQUE INDEX index_name
on table_name (column_name);
3.3 组合索引组合索引是基于一个表的两个或多个列上创建的索引。基本语法如下:
CREATE INDEX index_name
on table_name (column1, column2);
是否要创建一个单列索引还是组合索引,要考虑到您在作为查询过滤条件的 WHERE 子句中使用非常频繁的列。
如果值使用到一个列,则选择使用单列索引。如果在作为过滤的 WHERE 子句中有两个或多个列经常使用,则选择使用组合索引。
3.4 隐式索引隐式索引是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
3.5 什么情况下要避免使用索引?虽然索引的目的在于提高数据库的性能,但这里有几个情况需要避免使用索引。使用索引时,应重新考虑下列准则:
- 索引不应该使用在较小的表上。
- 索引不应该使用在有频繁的大批量的更新或插入操作的表上。
- 索引不应该使用在含有大量的 NULL 值的列上。
- 索引不应该使用在频繁操作的列上。
4. SQLite 事务(Transaction)
事务(Transaction)是一个对数据库执行工作单元。事务(Transaction)是以逻辑顺序完成的工作单位或序列,可以是由用户手动操作完成,也可以是由某种数据库程序自动完成。
事务(Transaction)是指一个或多个更改数据库的扩展。例如,如果您正在创建一个记录或者更新一个记录或者从表中删除一个记录,那么您正在该表上执行事务。重要的是要控制事务以确保数据的完整性和处理数据库错误。
实际上,您可以把许多的 SQLite 查询联合成一组,把所有这些放在一起作为事务的一部分进行执行。
4.1 事务的属性( ACID)事务(Transaction)具有以下四个标准属性,通常根据首字母缩写为 ACID:
- 原子性(Atomicity):确保工作单位内的所有操作都成功完成,否则,事务会在出现故障时终止,之前的操作也会回滚到以前的状态。
- 一致性(Consistency):确保数据库在成功提交的事务上正确地改变状态。
- 隔离性(Isolation):使事务操作相互独立和透明。
- 持久性(Durability):确保已提交事务的结果或效果在系统发生故障的情况下仍然存在。
使用下面的命令来控制事务:
- BEGIN TRANSACTION:开始事务处理。
- COMMIT:保存更改,或者可以使用 END TRANSACTION 命令。
- ROLLBACK:回滚所做的更改。
事务控制命令只与 DML 命令 INSERT、UPDATE 和 DELETE 一起使用。他们不能在创建表或删除表时使用,因为这些操作在数据库中是自动提交的。
4.2.1 BEGIN TRANSACTION 命令事务(Transaction)可以使用 BEGIN TRANSACTION 命令或简单的 BEGIN 命令来启动。此类事务通常会持续执行下去,直到遇到下一个 COMMIT 或 ROLLBACK 命令。不过在数据库关闭或发生错误时,事务处理也会回滚。以下是启动一个事务的简单语法:
BEGIN;
or
BEGIN TRANSACTION;
4.2.2 COMMIT 命令COMMIT 命令是用于把事务调用的更改保存到数据库中的事务命令。
COMMIT 命令把自上次 COMMIT 或 ROLLBACK 命令以来的所有事务保存到数据库。
COMMIT 命令的语法如下:
COMMIT;
or
END TRANSACTION;
4.2.3 ROLLBACK 命令ROLLBACK 命令是用于撤消尚未保存到数据库的事务的事务命令。
ROLLBACK 命令只能用于撤销自上次发出 COMMIT 或 ROLLBACK 命令以来的事务。
ROLLBACK 命令的语法如下:
ROLLBACK;
5. SQLite 约束约束是在表的数据列上强制执行的规则。这些是用来限制可以插入到表中的数据类型。这确保了数据库中数据的准确性和可靠性。
约束可以是列级或表级。列级约束仅适用于列,表级约束被应用到整个表。
以下是在 SQLite 中常用的约束。
- NOT NULL 约束:确保某列不能有 NULL 值。
- DEFAULT 约束:当某列没有指定值时,为该列提供默认值。
- UNIQUE 约束:确保某列中的所有值是不同的。
- PRIMARY Key 约束:唯一标识数据库表中的各行/记录。
- CHECK 约束:CHECK 约束确保某列中的所有值满足一定条件。
子查询或内部查询或嵌套查询是在另一个 SQLite 查询内嵌入在 WHERE 子句中的查询。
使用子查询返回的数据将被用在主查询中作为条件,以进一步限制要检索的数据。
子查询可以与 SELECT、INSERT、UPDATE 和 DELETE 语句一起使用,可伴随着使用运算符如 =、<、>、>=、<=、IN、BETWEEN 等。
以下是子查询必须遵循的几个规则:
- 子查询必须用括号括起来。
- 子查询在 SELECT 子句中只能有一个列,除非在主查询中有多列,与子查询的所选列进行比较。
- ORDER BY 不能用在子查询中,虽然主查询可以使用 ORDER BY。可以在子查询中使用 GROUP BY,功能与 ORDER BY 相同。
- 子查询返回多于一行,只能与多值运算符一起使用,如 IN 运算符。
- BETWEEN 运算符不能与子查询一起使用,但是,BETWEEN 可在子查询内使用。
子查询通常与 SELECT 语句一起使用。基本语法如下:
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
6.2 INSERT 语句中的子查询使用子查询也可以与 INSERT 语句一起使用。INSERT 语句使用子查询返回的数据插入到另一个表中。在子查询中所选择的数据可以用任何字符、日期或数字函数修改。
基本语法如下:
INSERT INTO table_name [ (column1 [, column2 ]) ]
SELECT [ *|column1 [, column2 ]
FROM table1 [, table2 ]
[ WHERE VALUE OPERATOR ]
6.3 UPDATE 语句中的子查询使用子查询可以与 UPDATE 语句结合使用。当通过 UPDATE 语句使用子查询时,表中单个或多个列被更新。
基本语法如下:
UPDATE table
SET column_name = new_value
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
6.4 DELETE 语句中的子查询使用子查询可以与 DELETE 语句结合使用,就像上面提到的其他语句一样。
基本语法如下:
DELETE FROM TABLE_NAME
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
,