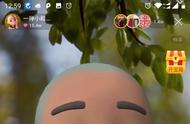
使用不同算法将人物的脖子向右旋转 15°
上图展示了对人物脖子进行旋转操作的情况,旋转后她一部分原本被遮挡的长发会变得可见。可以看到,Pumarola et al. 的算法会得到模糊的人脸。我推测原因是该网络需要根据压缩的特征编码生成所有新像素,这可能会丢失原图像中的高频细节。之前其它一些编码器-解码器架构的研究也观察到了类似的行为,比如 Tatarchenko et al. 和 Park et al.。
Zhou et al. 则是复用输入图像的像素,因此能够产生清晰的结果。然而,通过复制已有像素难以重建之前被遮挡的部分,尤其是所要复制的位置距离很远时。在上图 b 中可以看到,Zhou et al. 的算法使用了手臂的像素来重建去除遮挡后的头发。另一方面,Pumarola et al. 方法得到的头发颜色更自然。
通过组合这两个算法的输出,我们可以得到好得多的结果:可见像素调整位置后会保持原有的清晰度,去除遮挡部分的像素也能获得自然的颜色。下图展示了组合器网络的架构。

- 组合器的架构
这个组合器网络的主体是 U-Net,这有助于对每个像素进行操作。然后它的输出会被变换成两个 α 掩码和一张变化图像。其中第一个 α 掩码会被用于组合两张输入图像。然后,第二个 α 掩码和变化图像则会与前一步的输出组合,得到最终结果。最后一步是对组合得到的图像进行修正,以提升其质量。
为了减少内存用量,这个组合器是与双算法旋转器分开训练的。我在所有训练样本上运行了后者,从而生成前者的输入。同样,我实验了两个损失函数。第一个是 L1 损失。

第二个是感知损失:

这个训练流程类似于人脸变形器的训练过程。但是,为了方便,这个训练仅进行了 3 epoch,而非 6 epoch。使用 L1 损失时批大小为 20,训练消耗了一天时间。使用感知损失时,批大小为 12,训练持续了两天时间。
评估定量评估
表现评估使用了两个指标。第一个是网络的输出与基本真值图像之间的平均每像素均方根误差(RMSE)。第二个是平均结构相似度指数(SSIM)。分数使用测试数据集中的 10 000 个样本计算得到。