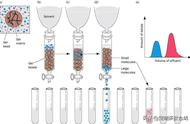
对于深度模型召回来说,需要有特定的架构模式来应对,我们的解决方案如下图所示。
模型训练为离线实时训练得到用户与item两侧的参数或embedding数据,参数部分依靠微信基础平台部提供的强大在线feature KV系统进行实时存取,user与item在线进行KNN计算实时查询最近领结果作为召回结果,其中KNN服务由基础平台部基于对Facebook开源的faiss升级改造的一套系统,可以在5ms内完成千万级内容的快速查找。

1. 序列模型
推荐系统主要解决的是基于用户的隐式阅读行为来做个性化推荐的问题,所以,我们尝试的方法是将用户在隐式阅读场景下表现出的点击文章序列构建为一个长文本,这样阅读文章和点击可以当做是文档的Term。
那么无数的用户阅读历史序列就可以当作是天然的语料库,如此可以将隐式推荐问题迁移为自然语言处理中的语义(语言)模型可cover的范畴。
基于神经网络模型学习得到Word2Vec模型,再后面的基于RNN的语言模型,这些方法都可以应用到语料的学习中。此外,seq2seq的机器翻译模型也可以帮助我们挖掘更多额外的信息。
2. N-Gram 语言模型
当然我们还有可以使用最基本和最经典的语言模型N-Gram模型来挖掘这批语料,考虑计算2-gram,3-gram,可以帮助我们了解item之间的转移概率信息。此外近几年提出的Word2Vec的模型可以看作是从另外一个维度去描述判断N-Gram的语言模型,Word2Vec的模型可以将term表达成一个稠密的向量,保存了语义信息,被认为是更加突出的语言模型。
3. RNN-based的语言模型
Rmb(rnn model based recommend)使用循环神经网络对用户阅读序列信息建模,捕捉用户阅读的序列关系和长期阅读兴趣的起止。训练时使用用户阅读序列和文章语义信息,线上使用循环神经网络预测topk进行召回。
基于循环神经网络的推荐模型(Recurrent Based Recommendation)是对用户阅读顺序使用循环神经网络的方法进行建模。该模型解决了在相同用户属性和相同阅读集合的情况下召回内容同质的问题,rmb可以对用户阅读顺序进行建模,即使相同用户属性,相同阅读集合的用户,如果他们阅读内容的顺序不同,也会有不同的召回结果。rmb可以对长期用户阅读历史和序列信息进行很好的建模。
为了更好使深度神经网络模型进行学习,首先使用item embedding方法将文章或者视频的ID映射到一个固定维度的稠密向量空间中,然后根据用户的阅读行为和文章的语义,对用户阅读序列进行建模。

4. 使用基于seq2seq的encoder-decoder模型
用户的阅读历史可以通过Session的切分原则划分为很多个Document,也就是说我们可以将一个用户抽象为文档序列。
给定一个文档序列,可以预测用户接下来的阅读序列,在这里我们将利用seq2seq来解决这个预测问题,将用户的阅读历史进行encoder,然后decoder出一个新的序列来作为推荐候选集。
在预测的过程中我们将文档中词的Embedding向量组合成一个文章的向量,基于用户的阅读历史序列可以进行有监督的学习,优化词的Embedding向量。
这种思想借鉴了Seq2Seq,我们可以考虑使用用户的前半部分session预测用户的后半部分session。这些都是类似机器翻译的NLP技术,我们坚信这种策略能够为我们提供合理有效的序列推荐。

5. Translation模型
在自然语言处理领域,神经机器翻译(Neural Machine Translation,NMT)模型大大提升了机器翻译的质量,使得机翻译文在忠实度、流利度方面首次超越人类专业译员。我们知道推荐业务中,线上粗排和精排的多队列融合加权,导致策略最终曝光量和多样性会明显下降。
因此,我们考虑基于NMT模型来提升线上视频推荐结果的多样性,主要原因有以下两点:
- NMT建模处理较长序列(长度> 30),一方面,可以将时间、地点等Context信息、以及video自身的语义信息融合到用户的点击序列中,供模型学习;另一方面,根据用户和video相关Context信息,对用户进行视频推荐。从两个方面提升视频推荐结果的独立性和多样性。
- NMT可以同时对item点击序列中item之间的局部和全局依赖关系进行建模,可以召回存在远距离依赖关系且用户感兴趣的item,丰富对推荐item的多样性。