首先一类是:Memory-based approach(图中是Neighborhood-based),当时尝试的这类协同过滤计算,思路为:“邻居”的思想,分为User-based CF(简称UserCF)和Item-based CF(简称ItemCF)。
在前期阶段中,行为 id维度构建的item cf 与user cf都有明显的在线效果提升,历史上在线曝光占比一度非常高。但是这类方法依赖item或user维度有大量行为累计,否则泛化和推荐能力很差,且具有很强的驱热性问题。
另一类,即考虑item内容信息的content-base approach类,即内容协同:我们称为ContentBase(解决夸内容域的各类相关计算场景的一类召回)。
看一看场景中有非常多语义相关的应用场景,例如:相关推荐、去重、打散、召回/排序特征等等。我们解决跨域的语义相关问题,整理出一套统一框架,方便统一调用使用。
架构整体为三层,相关算法层,并行优化层和算法接口层。整体相关性框架如下图所示:

我们使用深度语义匹配模型来进行文本相关性的计算,主要通过embedding、滑动窗口、CNN、MaxPolling,前馈网络,最终通过余弦距离计算两个文本的相似度,如下图所示:

线上的item聚类算法的难点是如何在几十ms内完成上百篇文档的聚类相似度计算、语义相似内容召回等算法,我们在并行优化层进行了“并集查询加速”,“相似漏斗形加速”,“多线程”加速等多点优化。目前也已经服务化,满足推荐场景下复用,落地看一看场景内各类相关性场景。
随后,我们上线了Model-based approach,在这种方法中,重要的思路为利用模型来预测用户对未评估item的评分。
有许多Model-based CF算法:贝叶斯网络( Bayesian networks),聚类模型( clustering models),隐语义模型(LFM),如奇异值分解(SVD),概率隐语义分析( probabilistic latent semantic analysis),多乘法因子(multiple multiplicative factor),latent Dirichlet allocation(LDA)和基于马尔可夫决策过程类模型(Markov decision process based models)。
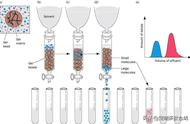
例如,我们在线的一种比较有效的方案:BPR(Bayesian Personalized Ranking from Implicit Feedback)其核心原理非常自然:将user-item序列(可以是任意点击,阅读,收藏行为)转化为item-item 的knn标注矩阵,如图:

方法中构造训练数据考虑的feature-item包括三类:
对于某个用户来说,在训练时都被标为”0″的item,在预测时的评分也可以排序,因此不影响ranking任务的完成。在我们系统实践时也没必要使用全部历史数据,只需要以session切片,从中按照上述形式构造pair-wise数据即可
通过这类方法,降维方法大多被用作补充技术来提高基于内存的方法的鲁棒性和准确性。
另外一方面,对于像奇异值分解,主成分分析等方法,根据潜在因素将用户项目矩阵压缩成低维表示。使用这种方法的一个优点是,更好地处理原始矩阵的稀疏性。
此外,对于处理大型稀疏数据集时我们下文也会介绍,借助大规模knn能力,这类矩阵相关性的计算可以得到很好的解决,非常适合召回场景。
第三类是Hybrid models(也就是前两种的混合模型)。许多应用程序结合了memory-based CF算法和model-based CF算法。这些方法克服了原生CF方法存在的局限性并提高了预测性能。其实上,这部分的进一步尝试,已经归类和被为下文将要介绍的深度模型召回所替换。
社交类召回,是微信场景下的特色数据,比如:
基于自然好友的:在看。
基于兴趣的:在看,XXX为基于兴趣关系得到的聚蔟关系。
又比如18年10月上线的在看频道:基于用户主动点击在看按钮,收集效果一类社交阅读场景。
3. 试探类召回
随着业务发展与对用户理解的深入,出现几类问题亟待解决:用户获取信息通常表现出很强的短期效应;我们在线通过引入用户实时阅读历史数据,利用短期阅读行为信息作为触发源,构建隐语义类召回策略。
但同时,我们很快发现,点击类指标提升带来的代价是短期内容集中,内容类型快速收敛,主要原因也是策略过于依赖短期行为,召回内容的集中,导致上层模型快速收敛,用户行为收敛,逐步导致很强的信息茧房效应。
召回测试是急需引入更为泛化与具备试探能力的召回。随着业务dau逐步提升,不断有新用户、新内容引入系统,如何解决冷启问题也需要着重考虑。
1)知识图谱类
在微信生态中,即使对于一个看一看新用户,我们也可以根据极少的用户/内容基本信息进行推荐。内容协同使用了异构网络的方法进行文章召回。