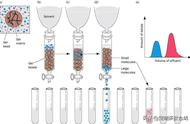
GraphSAGE首先通过采样(Sample),从构建好的网络中抽取出一个子图:随机采样一个源结点V1,然后采样它的一阶邻接结点V2、V5,在采样它的一阶结点的一阶结点(源节点的二阶结点)。
然后进行一个反向的信息聚合(Aggregation):以源节点的二阶结点原始Embedding作为输入,通过聚合2得到源节点的邻居结点的表示,然后再通过聚合1得到源节点V1的表示。聚合得到结点的表示之后,通过Pair-Wise的无监督损失函数,或者有监督的交叉熵损失函数训练网络的参数。
GAT(Graph Attentional Neural Network)模型介绍:
GraphSAGE虽然能让你更有效聚合结点信息,但它在进行结点信息聚合的时候存在一个明显不足:把所有的邻接结点都看成相同的权重,忽略了不同结点间重要程度的区分。
因此,我们引入了Attention机制对GraphSAGE模型进行升级,上线了GAT模型,在进行信息聚合的时候给不同的结点赋予不同的权重,以达到区分不同结点重要性的目标。
Attention机制的原理如下图中左侧图所示:

GAT模型的基本结构和GraphSAGE一样,分为采样和聚合两步,最大的区别是,GAT在完成结点采样,进行信息聚合的时候,通过传统的Vallina Attention,给不同的结点赋予不同的权重,以达到区分不同结点重要性的目标。
多任务Multi-GAT模型介绍:
看一看召回中,一些新的优化目标(比如用户分享行为)或新任务存在数据稀稀疏的问题。因此我们基于GAT-Multi进行多任务/目标的学习,将不同业务或不同类型的输入作为输入,输出端进行拆分,基于多目标或多任务提升embedding效果。
整个网络结构如下图所示:

从图中可以发现,模型输入是多种数据类型或多业务类型的混合数据输入,输出端根据不同的目标进行了拆分。输入是用户点击和分享构成的异构网络,输出端拆分成了点击和分享两个目标,并在损失函数中对分享目标进行了提权,目标期望通过用户的点击日志提升用户的分享行为指标。
六、总结与展望内容策略与召回通常验证收益路径长,见效慢,这样大大加大了这部分工作的协同开发的诉求,我们与工程同学经过无数次性能优化与PK,依赖兄弟团队提供了大量工具帮助,最终实现目前比较高效的一条迭代路径。
同时,由于召回与内容策略在业务底层,策略相对比较多,也比较发散,获得收益面通常也比上层要难,我的一些思考是,需要在工作中对这部分的工作梳理做足够细致归类,逐层优化,集中人力与优势精细打磨,持续沉淀核心部分,紧跟业界学术界前言算法,在兼顾满足业务发展的各类细碎需求的同时让算法同学获得成长与成就感。
相关阅读:
个性化推荐如何满足用户口味?微信看一看的技术这样做
作者:nevinzhang ;*微信AI
来源:https://mp.weixin.qq.com/s/s03njUVj1gHTOS0GSVgDLg
本文由 @ 微信AI 授权发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
,