Kubernetes的组成与原理
Kubernetes集群本身作为一个分布式系统,也采用了经典的Master-Slave架构,如下图所示,集群中有一个节点是Master节点,在其上部署了3个主要的控制程序:API Sever、ControllerManager 及 Scheduler,还部署了Etcd进程,用来持久化存储Kubernetes管理的资源对象(如Service、Pod、RC/Deployment)等。

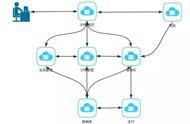
集群中的其他节点被称为Node节点,属于工人(Worker 节点),它们都由Master 节点领导,主要负责照顾各自节点上分配的Pod副本。下面这张图更加清晰地表明了Kubernetes各个进程之间的交互关系。

从上图可以看到,位于中心地位的进程是API Server,所有其他进程都与它直接交互,其他进程之间并不存在直接的交互关系。那么,APl Server的作用是什么呢?它其实是Kubernetes的数据网关,即所有进入Kubernetes 的数据都是通过这个网关保存到Etcd数据库中的,同时通过API Server将Eted里变化的数据实时发给其他相关的Kubernetes进程。API Server 以REST方式对外提供接口,这些接口基本上分为以下两类。
- 所有资源对象的CRUD API:资源对象会被保存到Etcd中存储并提供Query接口,比如针对Pod、Service及RC等的操作。
- 资源对象的 Watch API:客户端用此API来及时得到资源变化的相关通知,比如某个Service 相关的Pod实例被创建成功,或者某个Pod 状态发生变化等通知,Watch API主要用于Kubernetes 中的高效自动控制逻辑。
下面是上图中其他Kubernetes进程的主要功能。
- controller manager:负责所有自动化控制事物,比如RC/Deployment的自动控制、HPA自动水平扩容的控制、磁盘定期清理等各种事务。
- scheduler:负责Pod 的调度算法,在一个新的Pod被创建后,Scheduler根据算法找到最佳 Node节点,这个过程也被称为Pod Binding。
- kubelet:负责本Node节点上Pod实例的创建、监控、重启、删除、状态更新、性能采集并定期上报 Pod 及本机 Node节点的信息给Master节点,由于Pod实例最终体现为Docker'容器,所以Kubelet还会与Docker交互。
- kube-proxy:为 Service的负载均衡器,负责建立Service Cluster IP 到对应的Pod实例之间的NAT转发规则,这是通过Linux iptables实现的。
在理解了Kubernetes各个进程的功能后,我们来看看一个RC 从YAML定义到最终被部署成多个Pod 及容器背后所发生的事情。为了很清晰地说明这个复杂的流程,这里给出一张示意图。

首先,在我们通过kubectrl create命令创建一个RC(资源对象)时,kubectrl通过Create RC这个REST接口将数据提交到APl Server,随后API Server将数据写入Etcd里持久保存。与此同时,Controller Manager监听(Watch)所有RC,一旦有RC被写入Etcd中,Controller Manager就得到了通知,它会读取RC的定义,然后比较在RC中所控制的Pod 的实际副本数与期待值的差异,然后采取对应的行动。此刻,Controller Manager 发现在集群中还没有对应的Pod实例,就根据RC里的Pod模板(Template)定义,创建一个Pod并通过API Server保存到Etcd中。类似地,Scheduler进程监听所有 Pod,一旦发现系统产生了一个新生的Pod,就开始执行调度逻辑,为该Pod 安排一个新家(Node),如果一切顺利,该Pod就被安排到某个Node节点上,即Binding to a Node。接下来,Scheduler进程就把这个信息及 Pod状态更新到Etcd里,最后,目标Node节点上的Kubelet监听到有新的Pod被安排到自己这里来了,就按照Pod里的定义,拉取容器的镜像并且创建对应的容器。在容器成功创建后,Kubelet进程再把 Pod的状态更新为Running 并通过API Server更新到 Etcd 中。如果此 Pod还有对应的Service,每个Node上的Kube-proxy进程就会监听所有Service及这些Service对应的Pod实例的变化,一旦发现有变化,就会在所在 Node节点上的 iptables 里增加或者删除对应的NAT转发规则,最终实现了Service的智能负载均衡功能,这一切都是自动完成的,无须人工干预。
那么,如果某个Node'宕机,则会发生什么事情呢?假如某个Node宕机一段时间,则因为在此节点上没有Kubelet进程定时汇报这些Pod 的状态,因此这个Node 上的所有Pod'实例都会被判定为失败状态,此时Controller Manager会将这些Pod删除并产生新的Pod实例,于是这些Pod被调度到其他 Node 上创建出来,系统自动恢复。
本节最后说说Kube-proxy的演变,如下图所示。