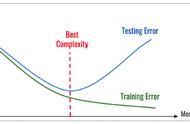
机器学习是计算机科学中最引人入胜的领域之一。
它在许多行业都有应用,任何人都可以学习。
在这篇博文中,我将为初学者介绍一些排名前 9 的机器学习模型,以便您开始使用 ML(机器语言)!

线性回归是您应该了解的首批机器学习模型之一。这是一种衡量变量如何相关的简单方法,这使得它很容易理解。
为什么使用线性回归?线性回归的主要好处是它非常易于解释。训练模型后,您可以轻松理解两个变量之间的关系,在某些情况下,当您需要解释您的机器学习模型如何做出欺诈检测或客户流失预测等决策时,这种方法效果很好。
线性回归方程是总结两个变量之间关系的好方法。它可用于根据另一个变量的已知值来预测一个变量的值。
应用您可以使用线性回归的实际应用程序包括:
- 根据平方英尺或卧室数量预测房屋价格
- 在给定库存水平和其他因素的情况下预测销售额
- 确定哪些变量对客户的购买决策很重要
2. 逻辑回归
逻辑回归是您应该尽早学习的另一种模型。当因变量是分类的(即只有有限数量的可能值)时,使用逻辑回归。
它可用于预测某事是否会发生(例如,某人是否会购买产品)或确定哪些因素在确定感兴趣的结果时最重要。
为什么要使用逻辑回归?逻辑回归的主要好处是比较容易解释结果。这是因为系数(即参数的估计值)对应于每个变量对结果预测的贡献程度。
简单来说,逻辑回归的工作原理是尝试找到最能将数据分成两组的线。一组由因变量等于 1 的所有情况组成(即预测他们将购买产品),另一组由因变量等于 0 的所有情况组成(即,预计他们不会购买该产品)。
应用您可以使用逻辑回归的实际应用程序包括:
- 确定哪些因素是决定学生成功的最重要因素
- 在给定库存水平和其他因素的情况下预测客户是否会购买产品
- 根据某人的喜好和其他个人详细信息确定是否会选择成为捐赠者。
3. 决策树
决策树是另一种常用于分类任务的机器学习模型。
它们通过将数据集拆分为越来越小的子集,直到每个子集仅包含具有相似属性的实例,这意味着您可以通过查看新示例相对于它们在此树结构中所处位置的特征来轻松分类新示例。
为什么使用决策树?决策树的主要好处是它们相对容易理解和解释。这是因为树状结构可以很容易地看出每个特征对新样本的分类有何贡献。
决策树的另一个好处是它们对过度拟合相对稳健,这意味着即使你有很多数据,它们仍然会做出很好的预测。这是因为树形结构有助于减少数据中的噪声并分离出不同类型的示例。
应用决策树可能有用的实际应用包括:
- 识别植物或动物的种类
- 预测房价
- 按照消费习惯对客户进行分组
4. 随机森林
随机森林是一种集成机器学习模型,这意味着它是通过组合多个模型来创建的。众所周知,集成方法特别擅长减少拟合
在随机森林的情况下,这涉及创建许多决策树,然后使用它们对每个实例中的最佳预测进行投票。
为什么要使用随机森林?使用随机森林的好处之一是它对过度拟合相对稳健,这意味着即使您有大量数据,它仍然可以做出良好的预测。这是因为森林中的单个决策树能够抵消数据中的一些噪声。
使用随机森林的另一个好处是它相对容易解释。这是因为可以单独查看每个决策树,并且可以使用称为“森林图”的图形来可视化它们之间的交互。
应用随机森林可能有用的实际应用包括:
- 预测葡萄酒的质量
- 分类星系
- 确定某人将来是否可能患上糖尿病
5. K-NN最近邻
k 最近邻算法 (kNN) 是一种简单的机器学习模型,它存储所有可用案例并通过与这些已知案例的相似性对新案例进行分类。
它们的工作方式是查看一组训练示例的属性,然后使用这些信息来预测新示例是否具有与这些已知案例相似或不同的属性。
即使您只有少量数据,这也使他们能够做出良好的预测。
为什么使用 K-NN近邻?k-NN 的主要优点是运行非常快速和高效,适合在大型数据集上使用。
应用k-NN 可能有用的实际应用包括:
- 根据过去的交易预测客户行为
- 出于营销目的将客户划分为不同的群体
- 使用医学图像确定肿瘤是良性还是恶性
6.朴素贝叶斯
朴素贝叶斯算法是一种简单的分类算法,常用于文本分类。它基于贝叶斯定理,可用于分类和回归任务。
他们的工作方式是使用统计方法来预测一个新的例子是属于一个类别还是另一个类别,基于它被分配的特征。
为什么使用朴素贝叶斯?朴素贝叶斯模型的一个优点是您不需要像其他模型那样多的数据来获得良好的预测。
这是因为他们能够从不同示例之间的相似性中学习,而不会被数据集中不相关的细节所迷惑。
应用朴素贝叶斯可能有用的实际应用包括:
- 根据内容识别垃圾邮件
- 预测某人会说的下一个词
- 动物图片分类
7. K-Means 聚类
K-Means 聚类是一种用于聚类分析的技术,它是将数据点分组到聚类中的过程。它可用于识别数据中的模式并提高机器学习模型的性能。
为什么使用 K-Means 聚类?k-means 聚类的一个优点是它非常快速且计算效率高。这使它成为迭代提炼集群的一种很好的技术,并且经常用于交互式数据挖掘。
k-means 聚类的准确性取决于您选择查看的聚类数量以及这些聚类的定义方式。但是,通过在算法初始化阶段选择合适的聚类中心,您可以提高其预测能力
应用K-Means 聚类通常用于:
- 识别客户群
- 根据联系人或连接分割的社交网络
- 将大型数据集划分为预定数量的集群
8. 支持向量机
支持向量机 (SVM) 是一种监督学习算法,可用于分类和回归任务。
它创建了一个超平面来分离数据集中不同类别的数据,最大限度地扩大它们之间的距离,同时尽量减少错误分类示例造成的错误。
支持向量机已被证明可以很好地处理高维数据,并且通常用于文本分类或图像识别任务。
为什么要使用支持向量机?支持向量机的一个优点是它们能够很好地从训练数据泛化到新示例。这使得它们不太可能过度拟合您训练它们的数据,并在实践中获得更好的性能。
与其他机器学习算法相比,它们的训练速度也相对较快。
应用支持向量机的实际应用包括:
- 将单词识别为句子中的名词或动词
- 将图像分类为汽车或卡车
- 识别一个人的讲话
9. 主成分分析
主成分分析 (PCA) 是一种用于减少数据集中维数的技术。
它通过识别主成分来做到这一点,主成分是解释数据差异最大的方向。PCA 可用于简化数据可视化并提高机器学习模型的性能。
为什么使用主成分分析使用 PCA 的主要好处是它减少了数据集中的维数。这使得数据可视化变得更加容易,同时防止过度拟合并提高模型性能。
其他好处包括:
- 与线性模型一起使用时提高了预测准确性
- 计算量低于 k-means 聚类
- 有助于识别数据中的重要特征
感谢您的阅读。
,