redis使用规范建议
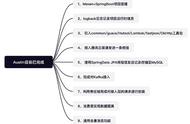
key命名规范

key命名规范
- 把业务名作为前缀, 然后用冒号分隔,再加上具体的业务数据名比如,存储页面1991的uv。key设计为:uv:page:1991
- key不要太长。保证可读性的情况下,尽量简写减少内存的损耗
Redis 是使用单线程读写数据,bigkey 的读写操作会阻塞线程,降低 Redis 的处理效率。
- 对于string类型的value,尽量保持10k以下
- 对于集合类型。尽量将集合的元素个数控制在1万以下
如果业务层的 String 类型数据确实很大,我 们还可以通过数据压缩来减小数据大小;
如果集合类型的元素的确很多,我们可以将一个 大集合拆分成多个小集合来保存。
使用整数对象共享池整数是常用的数据类型,Redis 内部维护了 0 到 9999 这 1 万个整数对象,并把这些整数 作为一个共享池使用。
换句话说,如果一个键值对中有 0 到 9999 范围的整数,Redis 就不会为这个键值对专门 创建整数对象了,而是会复用共享池中的整数对象。
基于这个特点,在满足业务数据需求的前提下,能用整数时就尽量用整数,这 样可以节省内存
使用redis保持热数据不同业务实例隔离数据保存时尽量设置过期时间控制单个 Redis 实例的容量Redis 单实例的内存大小都不要太大,根据我自己的经验值,建议你设置在 2~6GB
线上禁用不安全命令一些涉及大量操作、耗时长的命令,就会严 重阻塞主线程,导致其它请求无法得到正常处理,主要是这三个:
keys,flushall,flushdb
管理员用 rename-command 命令在配置文件中对这些命令进行重命名。
慎用monitor命令慎用全量操作命令对于集合类型的数据来说,如果想要获得集合中的所有元素,一般不建议使用全量操作的 命令(例如 Hash 类型的 HGETALL、Set 类型的 SMEMBERS)。
这些操作会对 Hash 和 Set 类型的底层数据结构进行全量扫描,如果集合类型数据较多的话,就会阻塞 Redis 主 线程。
- 可以使用 SSCAN、HSCAN 命令分批返回集合中的数据
- 可以化整为零,把一个大的 Hash 集合拆分成多个小的 Hash 集合。