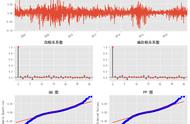
Accuracy: 0.8904109589041096
决策树用于特征创造
将每日来盘价、收盘价、交易量等进行环比,得到每天是增是减的分类型变量。
# 创造更多的时间
dataset['Open_N'] = np.where(dataset['open'].shift(-1) > dataset['open'],'Up','Down')
dataset['High_N'] = np.where(dataset['high'].shift(-1) > dataset['high'],'Up','Down')
dataset['Low_N'] = np.where(dataset['low'].shift(-1) > dataset['low'],'Up','Down')
dataset['Close_N'] = np.where(dataset['close'].shift(-1) > dataset['close'],'Up','Down')
dataset['Volume_N'] = np.where(dataset['volume'].shift(-1) > dataset['volume'],'Positive','Negative')
dataset.head()

X = dataset[['Open', 'Open_N', 'Volume_N']].values
y = dataset['Up_Down']
from sklearn import preprocessing
le_Open = preprocessing.LabelEncoder()
le_Open.fit(['Up','Down'])
X[:,1] = le_Open.transform(X[:,1])
le_Volume = preprocessing.LabelEncoder()
le_Volume.fit(['Positive', 'Negative'])
X[:,2] = le_Volume.transform(X[:,2])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
模型建立与预测
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
# 实例化模型
Up_Down_Tree = DecisionTreeClassifier(criterion="entropy", max_depth = 4)
Up_Down_Tree
Up_Down_Tree.fit(X_train,y_train)
# 预测
predTree = Up_Down_Tree.predict(X_test)
print(predTree[0:5])
print(y_test[0:5])
['Up' 'Up' 'Up' 'Up' 'Down']
date
2019-12-31 Up
2019-12-25 Up
2018-01-11 Up
2020-08-21 Down
2019-11-20 Down
Name: Up_Down, dtype: object
决策树可视化
from sklearn.tree import DecisionTreeClassifier
from IPython.display import Image
from sklearn import tree
# pip install pydotplus
import pydotplus
# 创建决策树实例
clf = DecisionTreeClassifier(random_state=0)
X = dataset.['open', 'high', 'low', 'volume', 'Open_Close', 'High_Low',
'Increase_Decrease', 'Buy_Sell_on_Open', 'Returns']
y = dataset['Buy_Sell']
# 训练模型
model = clf.fit(X, y)
# 创建 DOT data
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=X.columns,
class_names=X.columns)
# 绘图
graph = pydotplus.graph_from_dot_data(dot_data)
# 展现图形
Image(graph.create_png())

这里展示了整个决策树决策过程,这里看似很不清晰,但放大后,能看清每个小框框的内容:分类规则、基尼指数、样本数、类别标签等等详细内容。

支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;
SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
SVM还包括核技巧,这使它成为实质上的非线性分类器。
Sklearn中实现SVM也是比较方便。
from sklearn.svm import SVC # "Support Vector Classifier"
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
model = SVC(kernel = 'rbf', C = 1000,gamma=0.001)
model.fit(X_train, y_train)
svc_predictions = model.predict(X_test)
print("Accuracy of SVM using optimized parameters ", accuracy_score(y_test,svc_predictions)*100)
print("Report : ", classification_report(y_test,svc_predictions))
print("Score : ",model.score(X_test, y_test))
更多分类模型效果评价可参见该文中的评价指标。