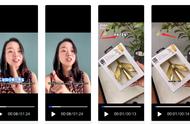
正如你所见,这个模型如此丝滑的表现让它在两个基准数据集上都实现了SOTA性能。

△ 与SOTA方法的对比
同时它的推理时间和计算复杂表现也很抢眼:
前者比此前的方法快了近15倍,可以在Titan XP GPU上以每帧0.12秒的速度处理432 × 240的视频;后者则是在所有比较的SOTA方法中实现了最低的FLOPs分数。
如此神器,什么来头?
改善光流法目前很多视频修复算法利用的都是光流法 (Optical flow)。
也就是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性,找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息。
这个方法的缺点很明显:计算量大、耗时长,也就是效率低。
为此,研究人员设计了三个可训练模块,分别为流完成 (flow completion)、特征传播 (feature propagation)和内容幻想(content hallucination),提出了一个流引导(flow-guided)的端到端视频修复框架:
E2FGVI。
这三个模块与之前基于光流的方法的三个阶段相对应,不过可以进行联合优化,从而实现更高效的修复过程。

具体来说,对于流完成模块,该方法直接在mask viedo中一步完成操作,而不是像此前方法采用多个复杂的步骤。
对于特征传播模块,与此前的像素级传播相比,该方法中的流引导传播过程在特征空间中借助可变形卷积进行。
通过更多可学习的采样偏移和特征级操作,传播模块释放了此前不能准确进行流估计的压力。
对于内容幻想模块,研究人员则提出了一种时间焦点Transformer来有效地建模空间和时间维度上的长程依赖关系。
同时该模块还考虑了局部和非局部时间邻域,从而获得更具时间相关性的修复结果。