要了解一致性哈希,首先我们必须了解传统的哈希及其在大规模分布式系统中的局限性。简单地说,哈希就是一个键值对存储,在给定键的情况下,可以非常高效地找到所关联的值。假设我们要根据其邮政编码查找城市中的街道名称。一种最简单的实现方式是将此信息以哈希字典的形式进行存储 <Zip Code,Street Name> 。
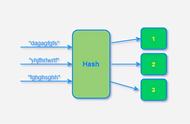
当数据太大而无法存储在一个节点或机器上时,问题变得更加有趣,系统中需要多个这样的节点或机器来存储它。比如,使用多个 Web 缓存中间件的系统。 那如何确定哪个 key 存储在哪个节点上?针对该问题,最简单的解决方案是使用哈希取模来确定。 给定一个 key,先对 key 进行哈希运算,将其除以系统中的节点数,然后将该 key 放入该节点。同样,在获取 key 时,对 key 进行哈希运算,再除以节点数,然后转到该节点并获取值。上述过程对应的哈希算法定义如下:
node_number = hash(key) % N # 其中 N 为节点数。
下图描绘了多节点系统中的传统的哈希取模算法,基于该算法可以实现简单的负载均衡。

阅读更多关于 Angular、TypeScript、Node.js/Java 、Spring 等技术文章,欢迎访问我的个人博客 —— 全栈修仙之路
一、传统哈希取模算法的局限性
下面我们来分析一下传统的哈希及其在大规模分布式系统中的局限性。这里我们直接使用我之前所写文章 布隆过滤器你值得拥有的开发利器 中定义的 SimpleHash 类,然后分别对 semlinker、kakuqo 和 test 3 个键进行哈希运算并取余,具体代码如下:
public class SimpleHash { private int cap; private int seed; public SimpleHash(int cap, int seed) { this.cap = cap; this.seed = seed; } public int hash(String value) { int result = 0; int len = value.length(); for (int i = 0; i < len; i ) { result = seed * result value.charAt(i); } return (cap - 1) & result; } public static void main(String[] args) { SimpleHash simpleHash = new SimpleHash(2 << 12, 8); System.out.println("node_number=hash(\"semlinker\") % 3 -> " simpleHash.hash("semlinker") % 3); System.out.println("node_number=hash(\"kakuqo\") % 3 -> " simpleHash.hash("kakuqo") % 3); System.out.println("node_number=hash(\"test\") % 3 -> " simpleHash.hash("test") % 3); } }
以上代码成功运行后,在控制台会输出以下结果:
node_number=hash("semlinker") % 3 -> 1 node_number=hash("kakuqo") % 3 -> 2 node_number=hash("test") % 3 -> 0
基于以上的输出结果,我们可以创建以下表格:

1.1 节点减少的场景
在分布式多节点系统中,出现故障很常见。任何节点都可能在没有任何事先通知的情况下挂掉,针对这种情况我们期望系统只是出现性能降低,正常的功能不会受到影响。对于原始示例,当节点出现故障时会发生什么?原始示例中有的 3 个节点,假设其中 1 个节点出现故障,这时节点数发生了变化,节点个数从 3 减少为 2,此时表格的状态发生了变化:

很明显节点的减少会导致键与节点的映射关系发生变化,这个变化对于新的键来说并不会产生任何影响,但对于已有的键来说,将导致节点映射错误,以 “semlinker” 为例,变化前系统有 3 个节点,该键对应的节点编号为 1,当出现故障时,节点数减少为 2 个,此时该键对应的节点编号为 0。
1.2 节点增加的场景
在分布式多节点系统中,对于某些场景比如节日大促,就需要对服务节点进行扩容,以应对突发的流量。对于原始示例,当增加节点会发生什么?原始示例中有的 3 个节点,假设进行扩容临时增加了 1 个节点,这时节点数发生了变化,节点个数从 3 增加为 4 个,此时表格的状态发生了变化: