本文作者:jeffhe,腾讯 IEG 开发工程师
1、什么是Hash提到hash,相信大多数同学都不会陌生,之前很火现在也依旧很火的技术区块链背后的底层原理之一就是hash,下面就从hash算法的原理和实际应用等几个角度,对hash算法进行一个讲解。
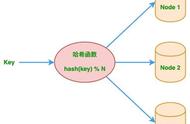
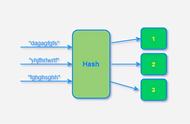
Hash也称散列、哈希,对应的英文都是Hash。基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出。这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。活动开发中经常使用的MD5和SHA都是历史悠久的Hash算法。
echo md5("这是一个测试文案");
// 输出结果:2124968af757ed51e71e6abeac04f98d
在这个例子里,这是一个测试文案是原始值,2124968af757ed51e71e6abeac04f98d就是经过hash算法得到的Hash值。整个Hash算法的过程就是把原始任意长度的值空间,映射成固定长度的值空间的过程。
一个优秀的hash算法,需要什么样的要求呢?
a)、从hash值不可以反向推导出原始的数据这个从上面MD5的例子里可以明确看到,经过映射后的数据和原始数据没有对应关系
b)、输入数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的值
echo md5("这是一个测试文案");
// 输出结果:2124968af757ed51e71e6abeac04f98d
echo md5("这是二个测试文案");
// 输出结果:bcc2a4bb4373076d494b2223aef9f702可以看到我们只改了一个文字,但是整个得到的hash值产生了非常大的变化。
c)、哈希算法的执行效率要高效,长的文本也能快速地计算出哈希值
d)、hash算法的冲突概率要小
由于hash的原理是将输入空间的值映射成hash空间内,而hash值的空间远小于输入的空间。根据抽屉原理,一定会存在不同的输入被映射成相同输出的情况。那么作为一个好的hash算法,就需要这种冲突的概率尽可能小。
3、Hash碰撞的解决方案桌上有十个苹果,要把这十个苹果放到九个抽屉里,无论怎样放,我们会发现至少会有一个抽屉里面放不少于两个苹果。这一现象就是我们所说的“抽屉原理”。抽屉原理的一般含义为:“如果每个抽屉代表一个集合,每一个苹果就可以代表一个元素,假如有n 1个元素放到n个集合中去,其中必定有一个集合里至少有两个元素。” 抽屉原理有时也被称为鸽巢原理。它是组合数学中一个重要的原理
前面提到了hash算法是一定会有冲突的,那么如果我们如果遇到了hash冲突需要解决的时候应该怎么处理呢?比较常用的算法是链地址法和开放地址法。
3.1 链地址法
链表地址法是使用一个链表数组,来存储相应数据,当hash遇到冲突的时候依次添加到链表的后面进行处理。

链地址在处理的流程如下:添加一个元素的时候,首先计算元素key的hash值,确定插入数组中的位置。如果当前位置下没有重复数据,则直接添加到当前位置。当遇到冲突的时候,添加到同一个hash值的元素后面,行成一个链表。这个链表的特点是同一个链表上的Hash值相同。Java的数据结构HashMap使用的就是这种方法来处理冲突,JDK1.8中,针对链表上的数据超过8条的时候,使用了红黑树进行优化。由于篇幅原因,这里不深入讨论相关数据结构,有兴趣的同学可以参考这篇文章:
《Java集合之一—HashMap》
3.2 开放地址法
开放地址法是指大小为 M 的数组保存 N 个键值对,其中 M > N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为“开放地址”哈希表。线性探测法,就是比较常用的一种“开放地址”哈希表的一种实现方式。线性探测法的核心思想是当冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。简单来说就是:一旦发生冲突,就去寻找下 一个空的散列表地址,只要散列表足够大,空的散列地址总能找到。
线性探测法的数学描述是:h(k, i) = (h(k, 0) i) mod m,i表示当前进行的是第几轮探查。i=1时,即是探查h(k, 0)的下一个;i=2,即是再下一个。这个方法是简单地向下探查。mod m表示:到达了表的底下之后,回到顶端从头开始。
对于开放寻址冲突解决方法,除了线性探测方法之外,还有另外两种比较经典的探测方法,二次探测(Quadratic probing)和双重散列(Double hashing)。但是不管采用哪种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子(load factor)来表示空位的多少。
散列表的装载因子=填入表中的元素个数/散列表的长度。装载因子越大,说明冲突越多,性能越差。
3.3 两种方案的demo示例
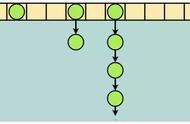
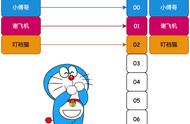
假设散列长为8,散列函数H(K)=K mod 7,给定的关键字序列为{32,14,23,2, 20}当使用链表法时,相应的数据结构如下图所示:

当使用线性探测法时,相应的数据结果如下图所示: