这里有一篇文章详细介绍了GeoHash,有兴趣的同学可以移步这里:
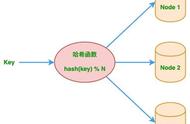
是什么能让 APP 快速精准定位到我们的位置?
5.3 布隆过滤器
布隆过滤器被广泛用于黑名单过滤、垃圾邮件过滤、爬虫判重系统以及缓存穿透问题。对于数量小,内存足够大的情况,我们可以直接用hashMap或者hashSet就可以满足这个活动需求了。但是如果数据量非常大,比如5TB的硬盘上放满了用户的参与数据,需要一个算法对这些数据进行去重,取得活动的去重参与用户数。这种时候,布隆过滤器就是一种比较好的解决方案了。
布隆过滤器其实是基于bitmap的一种应用,在1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难,主要用于大数据去重、垃圾邮件过滤和爬虫url记录中。核心思路是使用一个bit来存储多个元素,通过这样的方式来减少内存的消耗。通过多个hash函数,将每个数据都算出多个值,存放在bitmap中对应的位置上。
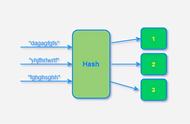
布隆过滤器的原理见下图所示:

上图所示的例子中,数据a、b、c经过三次hash映射后,对应的bit位都是1,表示这三个数据已经存在了。而d这份数据经过映射后有一个结果是0,则表明d这个数据一定没有出现过。布隆过滤器存在假阳率(判定存在的元素可能不存在)的问题,但是没有假阴率(判断不存在的原因可能存在)的问题。即对于数据e,三次映射的结果都是1,但是这份数据也可能没有出现过。
误判率的数据公式如下所示:

其中,p是误判率,n是容纳的元素,m是需要的存储空间。由公示可以看出,布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,则会导致误报率升高。
6、总结Hash算法作为一种活动开发经常遇到的算法,我们在使用中不仅仅要知道这种算法背后真正的原理,才可以在使用上做到有的放矢。Hash的相关知识还有很多,有兴趣的同学可以继续深入研究。