从本篇文章开始介绍一款现在非常火的分布式文件系统Ceph,包括这款文件系统的安装、基本使用场景、常用管理命令和重要工作原理。特别是讨论了PaxOS算法的基本理后,就更容易理解Ceph分布式文件系统中各种角色的工作原理。
2. Ceph的安装部署本文将介绍Ceph分布式文件系统如何在CentOS 7.X版本上一步一步完成安装,使读者在阅读过程中了解Ceph有哪些重要的子系统/工作模块,以及它们是如何关联工作的。请注意Ceph在Ubuntu等Linux操作系统上的安装过程和注意点大致相同,但如果读者和笔者同样选择在CentOS上安装Ceph,那么就请使用CentOS 7.X的版本,因为这个版本是Ceph官方介绍中推荐的,更重要的是CentOS 6.X已经不受支持了。
2-1. 准备工作
本文的演示中我们将按照以下表格安装一个三节点的Ceph分布式文件系统,并绑定一个文件系统的客户端进行文件读写操作。

以上表格中的角色缩写如果目前看不懂也无所谓,在后续的安装介绍中我们将说明这些功能角色的作用。Ceph的安装准备工作相对而言有一些繁琐,如果每一个节点都是全新的操作系统,那么这些节点至少需要经过创建用户、设置用户无密码登录权限、变更Ceph下载仓库、更新软件仓库等工作才能完成准备动作。其过程中往往会出现一些错误,需要在安装过程中耐心解决,下面我们就开始Ceph安装前的准备工作。
2-1-1. 关于用户
无论是测试环境还是正式环境,安装Ceph都不建议使用root账号。所以第一步我们需要专门创建一个用户和用户组,并为这个用户给定管理员权限。我们创建一个用户组ceph和一个专门用来运行Ceph各个模块的用户,用户名也叫做ceph
[......]# groupadd ceph
[......]# useradd ceph -g ceph
[......]# passwd ceph
// 修改成你想要的密码
......
记得为用户设置root权限,既是在sudoers文件中加入相关配置信息:
[......]# vim /etc/sudoers
// 加入ceph的sudo权限
......
root ALL=(ALL) ALL
ceph ALL=(ALL) NOPASSWD:ALL
......
参与Ceph构建的每个节点都要设置相同的用户信息,并且设置该用户在各个节点间的无密码登录功能——这是因为后面Ceph-deploy的工作过程中,将登录到各个节点上执行命令。
[ceph@vmnode1 ~]$ ssh-keygen
// 操作系统会出现一些提示,回车就行了
[ceph@vmnode1 ~]$ cd ~/.ssh/
[ceph@vmnode1 .ssh]$ cat ./id_rsa.pub >> ./authorized_keys
// 一定要更改authorized_keys的访问权限,不然无密码登录要失败
[ceph@vmnode1 ~]$ chmod 600 ./authorized_keys
// 将authorized_keys copy到你将要登录的操作系统上,注意用户的home目录要做对应
关于无密码登录的设置过程就不再深入讲解了,因为是很基本的ssh设置。主要原则就是保证authorized_keys文件的公钥记录信息和这个文件在几个节点间的一致性。如果后续有新的节点加入到Ceph集群中,并且也要承担MDS Follower角色的工作,则同样要设置这个新节点到各个节点的相互无密码登录功能。
2-1-2. 关于Ceph源和扩展组件
Ceph官网的下载速度奇慢(“https://download.ceph.com/“),这实际上不怪Ceph,原因大家也都懂,呵呵。一个办法是设置国外的代理服务,有免费的,不过好用的还是付费的。另一个好消息是,Ceph有国内镜像,例如163的和aliyun的。根据笔者观察163的镜像同步要比aliyun的镜像同步及时,比如163的镜像中已经有rpm-hammer/ceph-deploy-1.5.37的下载,但是aliyun的镜像中最高版本只有ceph-deploy-1.5.36。通过以下环境变量的设置就可以使用国内的镜像(这个过程不会影响后续的任何安装步骤):
# 你也可以改成国内其它Ceph镜像
export CEPH_DEPLOY_REPO_URL=http://mirrors.163.com/ceph/rpm-hammer/el7;
export CEPH_DEPLOY_GPG_URL=http://mirrors.163.com/ceph/keys/release.asc;
另外Ceph的安装过程还需要相当的第三方组件依赖,其中一些第三方组件在CentOS yum.repo Base等官方源中是没有的(例如LevelDB),所以读者在安装过程中会有一定的几率遇到各种依赖关系异常,并要求先行安装XXX第三方组件的提示(例如提示先安装liblevel.so)。虽然我们后文将会介绍的Ceph辅助部署工具,Ceph-deploy的工作本质还是通过yum命令去安装管理组件,但是既然CentOS yum.repo Base官方源中并没有某些需要依赖的第三方组件,所以一旦遇到类似的组件依赖问题安装过程就没法自动继续了。解决这个问题,本示例中建议引入CentOS的第三方扩展源Epel。
# 关于Epel 扩展源的引入这里不过做介绍了,网络上的资料一大把。这里给出一个“目前可用”(不保证多年后依然可用)的安装地址,以及安装后生成的repo配置片段(本示例中的第三方扩展源匹配CentOS 7.X操作系统)。
http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-9.noarch.rpm
# repo文件的名字叫做epel.repo
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
failovermethod=priority
enabled=1
gpgcheck=0
gpgkey=File:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
......
为了保证扩展源中的组件与CentOS官方源中的组件不冲突,可以调低扩展源的优先级。当然读者也可以自行手动解决Ceph安装过程提示的组件依赖问题——使用rpm命令的方式。笔者试过,深刻的体会到什么叫生不如死。。。
设置仓库后,需要更新仓库缓存,如下:
[......]$ yum makecache
[......]$ yum update
2-1-3. 关于物理磁盘
Ceph是一种分布式文件系统,既然是文件系统,那么无论它的上层如何设计如何划分,始终需要对数据持久化存储进行落地。所以Ceph需要操作块存储设备(关于块存储的相关介绍,可以参看本专题最初的几篇文章),Ceph要求块存储设备的文件系统必须为XFS、BTRFS或者EXT4,且必须在操作系统上有独立挂载点。
2-2. 正式安装
Ceph的安装有两种方式,第一种是使用Ceph官方提供的Ceph-deploy(部署工具)进行安装,这种方式我们需要首先yum Ceph-deploy,然后再使用Ceph-deploy提供的各种命令来安装Ceph的各个节点,但好处也很明显——Ceph的安装过程基本上是半自动化的,除了一些操作系统层面的问题需要解决外(例如用户对某个目录的读写权限设定错误,再例如防火墙的端口没有打开等等)整个过程还算比较顺利。另外一种是全人工安装,除非你的操作系统存在特殊应用场景,或者有需要特别保护的组件需要进行独立设定,否则还是建议使用前一种Ceph-deploy的方式。
2-2-1. 安装Ceph-Deploy和Ceph软件本身
首先安装ceph-deploy软件本省。请注意这个软件并不是ceph工作的一部分,它只一个增加简便性的工具。
......
[......]$ yum -y install ceph-deploy
// NTP时钟同步服务
[......]$ yum install -y ntp ntpdate ntp-doc
//使用一个亚洲公用时间同步节点进行时间同步
[......]$ ntpdate 0.asia.pool.ntp.org
......
只需要在某个节点上安装ceph-deploy就行,但是NTP服务是每一个节点都要安装和进行同步,它主要是保证各节点的物理时钟同步。接下来我们使用ceph-deploy工具在将要参与Ceph分布式文件系统的各个节点上,安装Ceph软件。注意,只是安装软件,并不是说完成后就可以让这些节点承担相应的工作职责了。以下命令只需要在安装了ceph-deploy的节点上执行就行了,ceph-deploy会帮助技术人员在指定的各个节点上使用yum命令安装ceph软件。接着使用以下命令在以上各个节点上正式安装Ceph软件:
[ceph@vmnode1 ~]$ ceph-deploy install vmnode1 vmnode2 vmnode3
// 命令格式为:
ceph-deploy install {ceph-node}[{ceph-node} ...]
安装Ceph软件的过程中,有一定概率会出现各种警告信息。警告信息有的是可以忽略的,有的则是必须进行处理的。这些问题一般分为几类:镜像源和下载问题,依赖问题,权限问题。如何来处理这些问题,除了需要具备一定的玩转Linux系统的经验外,主要还是细心,切忌急躁。
2-2-2. 安装Ceph Monitor
MON是Monitor的简称,字面意义为监控、监视。是的,它的作用是监控、管理和协调整个分布式系统环境中其它各个OSD/PG、Client、MDS角色的工作,保证整个分布环境中的数据一致性。注意,为了保证节点故障的情况下,整个Ceph分布式文件系统依然可以稳定工作,我们必须设置多个MON角色。例如在本示例中,就设置参与Ceph分布式系统的三个节点上,都安装MON角色:
// 改名了意味新的MON节点
[ceph@vmnode1 ~]$ ceph-deploy new vmnode1 vmnode2 vmnode3
// 命令格式为:
ceph-deploy new {initial-monitor-node(s)}
以上命令运行后,ceph-deploy工具会在本节点生成一些文件,包括:
ceph.conf
ceph.log
ceph.mon.keyring
最重要的文件当然就是ceph.conf文件了(实际上ceph.mon.keyring也很重要),观察这个文件内容:
[ceph@vmnode1 ~]$ cat ./ceph.conf
[global]
fsid = 50c157eb-6d74-4d7d-b8e8-959a7b855b55
mon_initial_members = vmnode1, vmnode2, vmnode3
mon_host = 172.16.71.182,172.16.71.183,172.16.71.184
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
可以看到ceph.conf文件中已经设置好了我们将要运行MON角色的三个节点信息。接下来我们还需要在ceph.conf文件中增加一些信息,如下(后文还会详细讲解ceph中的重要参数):
[ceph@vmnode1 ~]$ vim ./ceph.conf
......
# 后续的文章会详细讲解ceph中重要的配置项
osd pool default size = 2
osd pool default min size = 2
max open files = 655350
cephx cluster require signatures = false
cephx service require signatures = false
......
接着使用以下命令,就可以在conf文件中已配置的MON节点上启动MON服务了(前提是,这些节点已经成功安装了Ceph软件):
# 开始初始化运行mon节点。
[ceph@vmnode1 ~]$ceph-deploy mon create-initial
# 如果需要指定一些自定义的配置参数,可以采用如下格式(命令有详细的帮助信息)来启动
[ceph@vmnode1 ~]$ceph-deploy --overwrite-conf --cluster ceph mon create-initial
每一个Ceph分布式系统都会有一个名字,如果在创建MON时不给定这个名字就会默认为“ceph”。完成以上步骤后,ceph-deploy工具会在当前运行命令的目录下生成几个文件,这些文件都非常重要,请不要擅自改动。在随后的安装过程中ceph-deploy工具将按需将这些文件复制到对应角色的对应目录中去。
{cluster-name}.client.admin.keyring
{cluster-name}.bootstrap-osd.keyring
{cluster-name}.bootstrap-mds.keyring
{cluster-name}.bootstrap-rgw.keyring
2-2-4. 安装Ceph OSD
在Ceph中,最终进行块存储落地操作的节点叫做OSD(Object Storage Device),实际上OSD只是Ceph中进行块存储操作的若干技术的一个载体,基于它工作的RADOS、PG等模块的设计思路才更值得学习借鉴(后续的文章会着重讨论)。但是,我们要是都不先行把OSD安装好并让它运行起来,又怎么进行学些呢?上文已经提到Ceph的对于块存储设备的操作,只能基于XFS、BTRFS或者EXT4,,并且需要是独立的磁盘分区和挂载点。
我们需要在vmnode1、vmnode2、vmnode3三个测试节点上安装Ceph,这三个节点上提供给Ceph使用的磁盘分区都是/dev/sdb1,使用文件系统格式都为XFS,磁盘挂载点都是/user/cephdata。这里就不在上图,不在讲解如何进行磁盘分区和格式化了,读者可以根据自己的实际情况进行操作。以下命令用于使用ceph-deploy创建和初始化OSD节点:
[ceph@vmnode1 ~]$ ceph-deploy osd create vmnode1:/user/cephdata vmnode2:/user/cephdata vmnode3:/user/cephdata
......
[ceph@vmnode1 ~]$ ceph-deploy osd prepare vmnode1:/user/cephdata vmnode2:/user/cephdata vmnode3:/user/cephdata
# 命令格式如下:
# ceph-deploy osd create {ceph-node}:{path} ...
# ceph-deploy osd prepare {ceph-node}:{path} ...
ceph-node代表节点host名字,也可以直接使用IP,Path为挂载点的起始路径。如果有多个OSD节点的信息,则依次书写就行了。完成后使用以下命令启动这些OSD节点:
#启动OSD节点
[ceph@vmnode1 ~]$ ceph-deploy osd activate vmnode1:/user/cephdata vmnode2:/user/cephdata vmnode3:/user/cephdata
# 命令格式如下:
# ceph-deploy osd activate {ceph-node}:{path} ...
# 或者使用以下语句启动单个OSD节点也行
# ceph-disk -v activate --mark-init sysvinit --mount /user/cephdata/
# 你也可以使用以下命令,检查整个系统中OSD节点的状态
# sudo ceph --cluster=ceph osd stat --format=json
OSD节点启动成功后还可以通过很多方式检查它(们)是否正常工作。例如使用以下命令进行检查:
[ceph@vmnode1 ~]$ sudo ceph osd stat
osdmap e11: 3 osds: 3 up, 3 in
以上输出的信息很好理解了,唯一可能不清楚的就是“osdmap e11”这个信息。Ceph中的MON角色其中有一个重要的工作就是监控Ceph中所有的OSD节点的工作状态,例如哪些OSD节点退出了Ceph环境,哪些新的OSD节点需要加入到Ceph环境。MON中的OSD Map就负责记录这些状态。至于“e11”中的“e”是epoch的简称,中文意思就是“时代”,MON中的OSD Map信息是要提供给Ceph中其它角色进行查询的(例如Client、各个OSD节点本身),而由于是分布式环境(存在节点间被割裂的情况),所以并不能保证这些角色在第一时间拿到最新版本的OSD Map信息,这时就要求MON Leader中记录目前最新版本的OSD Map的版本信息,以便Ceph中各个角色能够确定自己当前记录的OSD Map是不是最新的,而每一个新版本都会使OSD Map的epoch信息 1。关于最新版本的epoch信息在整个Ceph中是怎么进行传播的,后文还会进行描述。
2-2-3. 建立MDS元数据
执行完以上步骤后,Ceph节点的主要安装过程实际上就已经完成了,但这个时候Ceph FS子系统还无法正常工作/无法被Client正常连接(使用原生mount或者FUSE方式,都不会挂载成功)。如果使用以下命令查看,将会返回类似信息:
[root@vmnode1 ~]# sudo ceph mds stat
e1: 0/0/0 up
大意是Ceph系统中有0个MDS角色,0个节点处于工作状态。这一小节的重要工作就是为Ceph系统创建MDS角色。首先我们通过ceph-deploy创建MDS节点:
[ceph@vmnode1 ~]$ ceph-deploy mds create vmnode1 vmnode2 vmnode3
注意MDS节点创建完成后不是说MDS角色就可以正常工作了,而只是说指定好了MDS角色将在哪些节点上进行工作。MDS角色的工作必须基于OSD Pool——MDS数据信息将在OSD节点上进行存储,所以我们还需要通过以下命令创建至少两个OSD Pool数据池:
[root@vmnode1 ~]# sudo ceph osd pool create cephfs_data 10
[ceph@vmnode1 ~]$ sudo ceph osd pool create cephfs_metadata 10
// 命令格式:
osd pool create <poolname> <int[0-]>
{<int[0-]>} {replicated|erasure}
{<erasure_code_profile>} {<ruleset>}
{<int>}
以上命令中“cephfs_data”表示OSD Pool的名称,而指定的“10”表示这个Pool所使用的PG数量,关于PG的定义和工作方式我们将在后续文章中进行介绍。那么我们为什么要创建名叫cephfs_data和cephfs_metadata的两个OSD Pool呢?这是因为其中一个OSD Pool要用来存储真实数据,另一个OSD Pool要用来存储元(Metadata)数据,而这些元数据将被MDS角色使用。接下来基于已建立的OSD Pool创建Ceph文件系统:
[root@vmnode1 ~]# sudo ceph fs new cephfs cephfs_metadata cephfs_data
// new fs with metadata pool 2 and data pool 1
// 命令格式为:
fs new <fs_name> <metadata> <data>
其中cephfs表示新创建的Ceph文件系统的名称,cephfs_metadata表示存储文件系统元数据(Metadata)所使用的OSD Pool,cephfs_data表示存储文件真实数据所使用的OSD Pool。以上关于建立MDS元数据更详尽的信息,可参见Ceph官方文档http://docs.ceph.com/docs/master/cephfs/createfs/部分的介绍。完成文件系统创建后,再次使用命令查看MDS角色状态,就可以看到以下信息:
[ceph@vmnode1 ~]$ sudo ceph mds stat
e4: 1/1/1 up {0=vmnode3=up:creating}, 2 up:standby
注意,MDS角色的工作原理是主备模式。也就是说加入的新的MDS节点将作为备用节点。你也可以使用如下命令,看到目前OSD Pool的使用情况:
[ceph@vmnode1 ~]$ sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
....M ....M ....M ....%
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 0 0
cephfs_data 1 0 0 0 0
cephfs_metadata 2 0 0 0 0
这里要多说一句,请注意使用ceph df命令查看Ceph文件系统OSD Pool状态时,即使技术人员没有创建自定义的OSD Pool,您也可以发现有一个已经存在的名叫rbd的OSD Pool。这个OSD Pool是为上层RBD子系统准备了,用于存储模拟的块设备中的映射信息,反映到Ceph支持的块存储功能上就是所谓的image映射文件。完成以上步骤后,可以使用以下命令,确定整个Ceph系统是健康的:
[ceph@vmnode1 ~]$ sudo ceph -s
cluster 50c157eb-6d74-4d7d-b8e8-959a7b855b55
health HEALTH_OK
至此,整个Ceph分布式文件系统关于服务端各个角色的安装、配置工作才算真正完成(还没有对参数项进行优化)。接下来我们就可以将一个或者多个Client连接到Ceph系统上进行使用了。
————————————————
3. 连接到Ceph系统3-1. 连接客户端
完成Ceph文件系统的创建过程后,就可以让客户端连接过去。Ceph支持两种客户端挂载方式:使用Linux内核支持的mount命令进行的挂载方式;使用用户空间文件系统FUSE(Filesystem in Userspace)进行的网络磁盘挂载方式。这两种挂载方式的本质区别是,前者需要有Linux内核的支持,而后者只是工作在Linux上的一个应用软件。
3-1-1. 使用mount命令进行挂载
这里要特别说明以下,CentOS 6.X和CentOS 7早期版本的内核都不支持使用mount命令直接进行Ceph分布式文件系统客户端的挂载,这主要是Kernel内核版本的原因,所以如果您发现您使用的操作系统有这个问题,就需要首先升级CentOS的版本(另外建议使用首先选用CentOS 7操作系统,或者版本较高的Ubuntu操作系统) 。关于Kernel内核版本升级的操作,后文也会进行介绍。另外从Kernel 3.10 版本开始(从其它网络资料上看,不用单独进行内核升级便可直接使用mount命令进行挂载的版本号,还可以往前推)。
还记得当上篇文章中,我们在介绍Ceph的安装过程时,曾经介绍了一个CentOS的第三方扩展源epel吗?在这个源中,还可以直接升级您CentOS 7操作系统的Kernel内核:
[.....]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
[.....]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
[.....]# yum install -y yum-plugin-fastestmirror
[.....]# yum --enablerepo=elrepo-kernel install kernel-ml kernel-ml-devel
[.....]# grub2-set-default 0
// 重启,一定要重启
[.....]# reboot
现在您可以使用CentOS 7 操作系统提供的mount命令,将Ceph分布式文件系统作为您的本地磁盘进行挂载了。但是在挂载之前还有最后一个步骤需要确认:您需要获得Ceph分布式文件系统给Client的权限信息。这个权限信息在文件“ceph.client.admin.keyring”中,这个文件在您安装的每个Ceph节点的“/etc/ceph”目录位置,另外,您还可以在运行ceph-deploy的安装节点的中,ceph用户的主目录下找到它:
// 可以在这里找到它
[.....]# sudo cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQDh991Y7T7hExAAYStCjopatfvUC /AEHqjcQ==
caps mds = "allow"
caps mon = "allow *"
caps osd = "allow *"
// 也可以在这里找到它
[ceph@vmnode1 ~]$ cat ./ceph.client.admin.keyring
[client.admin]
key = AQDh991Y7T7hExAAYStCjopatfvUC /AEHqjcQ==
caps mds = "allow"
caps mon = "allow *"
caps osd = "allow *"
接下来可以进行挂载了:
[root@client ~]# mkdir /mnt/cephclient
[root@client ~]# mount.ceph vmnode1:6789:/,vmnode2:6789:/,vmnode3:6789:/ /mnt/cephclient/ -o name=admin,secret=AQDh991Y7T7hExAAYStCjopatfvUC /AEHqjcQ==
// 或者以下命令也行
[root@client ~]# mount -t ceph vmnode1:6789:/,vmnode2:6789:/,vmnode3:6789:/ /mnt/cephclient/ -o name=admin,secret=AQDh991Y7T7hExAAYStCjopatfvUC /AEHqjcQ==
注意,请确保防火墙没有阻挡Ceph各个节点所使用的端口(不止包括6789这个端口)。以上的vmnode1、vmnode2、vmnode3表示MON角色所在的节点,注意携带的name参数和secret参数都来源于ceph.client.admin.keyring文件中的内容,其中name属性,对应文件中的“[client.admin]”,secret属性,对应文件中的“key”。您还可以直接将ceph.client.admin.keyring拷贝到Ceph Client节点,然后在挂载时,使用secretfile参数指定这个文件。
3-1-2. 使用FUSE进行挂载
ceph-fuse可以通过ceph-deploy进行安装,也可以使用yum命令进行安装。如果要运行ceph-fuse命令,Client节点上就必须要有ceph.conf和ceph.client.admin.keyring这两个文件。
// 记得首先设置ceph的安装镜像
[root@client ~]# yum install -y ceph-fuse
接着可以使用以下命名进行挂载:
[root@client ~]# ceph-fuse -m vmnode1,vmnode2,vmnode3 /mnt/cephclient/
同之前讲解的命令大致相同,vmnode1、vmnode2、vmnode3表示MON角色所在的节点。另外可以使用“-c” 参数指定ceph.conf文件所在位置,还可以使用”-k”参数指定ceph.client.admin.keyring文件所在位置。否则这两个文件就是放置在运行这个命令时,所在的目录下。例如以上示例中就是在root用户的工作目录/root/下运行ceph-fuse命令的。
3-2. 挂载时的常见问题
3-2-1. 关于error 5 = Input/output error
这个错误是Ceph Client在进行挂载操作时,最常见的一种错误。引起这类错误最直接的原因,就是Ceph分布式文件系统的健康状态不正确,或者换一个更明确的说法:使用“ceph -s”命令查看Ceph系统状态时,返回的信息不为“health HEALTH_OK”。
无论你是使用Linux操作系统原生的mount命令进行Ceph Client的挂载,还是使用Ceph-Fuse进行挂载,在挂载前必须确认Ceph系统的工作状态为“health HEALTH_OK”,其它任何带有警告信息、报错信息的状态返回,都会导致Ceph Client挂载失败。那么“error 5 = Input/output error”这个问题实际上就转变为了,Ceph文件系统的健康状态常见的错误有哪些了。
由MDS未启动或状态错误导致的:
您可以使用以下命令检查MDS的工作状态:
// 类似以下的MDS状态返回信息,说明MDS工作是正确的
[root@vmnode ~]# ceph mds stat
e95: 1/1/1 up {0=vmnode1=up:active}, 1 up:standby
// 而类似以下的MDS状态返回信息,说明MDS可能是有问题的,甚至还没有创建MDS角色
[root@vmnode ~]# ceph mds stat
e1: 0/0/0 up
由MON未启动或者状态错误导致的:
MON角色没有创建或者没有启动同样会导致Ceph集群工作状态错误,您可以使用以下命令检查MON的工作状态:
// 类似以下的MON工作状态反馈,说明MON角色是正常的
[root@vmnode ~]# ceph mon stat
e2: 3 mons at {vmnode1=......:6789/0,vmnode2=.......:6789/0,vmnode3=.......:6789/0}, election epoch 84, quorum 0,1,2 vmnode1,vmnode2,vmnode3
由于Ceph文件系统中MON角色采用主备(Leader/Follower)模式,所以只要有至少一个MON是在正常工作的就行。关于以上示例中查看MON工作状态的返回信息,也反映了MON的工作原理,我们将在后续文章中进行讲解。
由OSD未启动或者PG太少或者OSD Pool错误导致的:
从笔者使用Ceph的经验来看,OSD角色和OSD Pool是最容易出现问题的。其本质原因是对PG的设定可能需要按照实际情况进行更改,而一些技术人员不熟悉PG的工作原理。OSD的配置和常见问题我们也放到后文,用专门的章节进行说明。例如,类似以下的信息只能说明OSD在工作,并不能说明OSD上的PG没有问题:
[root@vmnode ~]# ceph osd stat
osdmap e48: 3 osds: 3 up, 3 in
由NTPD时间偏移导致的(出现概率很大):
Ceph分布式文件系统上的各个工作节点需要保证系统时间同步,Ceph默认能够容忍的各节点最大时间偏移量为0.05S,当然这个值可以进行设定,但不建议更改设定。类似以下的Ceph系统健康警告信息,就是由于节点间时间偏移较大导致的:
......
HEALTH_WARN clock skew detected on vmnode1; 8 requests are blocked > 32 sec; Monitor clock skew detected
......
另外您也可以使用以下命令查看Ceph文件系统的实时状态变化,如果发现有类似以下的警告,也说明Ceph各个节点间的系统时间偏移量过大:
[root@vmnode1 ~]# ceph -w
......
XXXXXXXXX mon.0 [WRN] mon.1 172.16.71.186:6789/0 clock skew 0.424674s > max 0.05s
......
我们一般使用Linux系统下的NTPD时间同步服务,来保证每个节点的时间同步,您可以运行ntpdate命令并保证Ceph系统中的所有节点都使用同一个时区服务。例如:
......
[root@vmnode ~]# ntpdate 0.asia.pool.ntp.org
// 运行完成后,最好重启ntpd服务
[root@vmnode ~]# service ntpd restart
注意以上命令并不是要求Linux系统立即同步时间,而只是设定了时间同步服务,所以会有一定的同步延迟,另外您还需要保证这个节点能够访问外部网络。如果仍然有关于时间偏移的健康警告,则重启整个Ceph系统。
另外你可以使用Ceph系统中的一个节点作为基准时间节点,然后其它节点的时间都已前者为准进行同步(这种方式网络上有很多资料可以参考)。或者可以使用以下命令进行强制同步:
[root@vmnode1 ~]# ntpdate -u asia.pool.ntp.org
XXXXXXX ntpdate[3864]: adjust time server 202.156.0.34 offset -0.073284 sec
由SELinux未关闭导致的:
SELinux是一种独立运行的访问控制功能,它能控制程序只能访问特定文件。笔者建议关闭Ceph分布式文件系统中,各个节点上的SELinux功能。首先,您可以通过以下命令查看SELinux功能是否在运行:
[root@vmnode ~]# sestatus
......
// 如果返回的信息中存在描述,则说明SELinux在工作
SELinux status: enabled
......
要关闭SELinux功能,需要修改“/etc/selinux/config”文件,将文件中的SELINUX=enforcing改为SELINUX=disabled,修改保存后一定要重启操作系统。
由其它问题导致的:
当然以上列举的导致Ceph健康状态异常的原因并不完整,例如也有可能是ceph.conf文件本身的读取权限设定问题,导致整个Ceph节点上的所有工作角色启动失败。本小节对于挂载失败情况下的问题总结也只是给各位读者一个排查问题的思路。是否能走完挂载Ceph文件系统的最后一步,还是要靠各位读者使用Ceph系统,甚至是使用LInux操作系统所积累的问题排查经验。后续文章中,我们将介绍Ceph分布式文件系统中各个重要角色的分工和工作原理,以及Ceph系统的配置优化项,这些知识总结都将更有助于读者排查日常工作中Ceph文件系统出现问题的原因。
3-2-2. 关于Ceph的日志
Ceph作为一款分布式文件系统/分布式对象存储系统,在IaaS层的应用已经越来越广泛。例如我们熟知的OpenStack,在其存储方案部分就允许使用Ceph替换掉Swift;而独立应用Ceph直接作为数据持久化存储方案的例子也很多,例如可以直接使用Ceph作为静态文件的存储方案、作为大数据分析过程中还未来得及做数据清理的原始文件(数据)的存储方案,在本专题之前介绍搭建自己的图片服务器文章时,就提到可以使用Ceph作为原始图片文件的持久化存储方案。再多说一句,这些文件不宜过小,如果存储规模在千亿级、万亿级,大小范围在1KB左右的文件,还是建议更换存储方案。后文在讨论了Ceph文件系统的工作原理后,我们再回头讨论Ceph文件系统对海量小文件(千亿级、万亿级)存储的支持。
既然Ceph在生产环境的地位越发重要,那么它的稳定性和可管理性也就越发重要了。好消息是Ceph文件系统提供了非常全面的日志功能,帮助我们进行日常运维管理。这些日志信息按照Ceph系统中的成员角色、工作节点和日志产生时间进行划分,默认的位置在Linux系统存放日志的目录中(当然您可以通过更改Ceph的配置项,改变Ceph输出日志文件的位置):
[root@vmnode1 ~]# ll /var/log/ceph/
......
-rw------- 1 root root 0 4月 13 09:28 ceph.audit.log
-rw------- 1 root root 1503 4月 11 04:26 ceph.audit.log-20170411.gz
-rw------- 1 root root 2098 4月 13 08:34 ceph.audit.log-20170413.gz
-rw------- 1 root root 133 4月 13 09:29 ceph.log
-rw------- 1 root root 1470 4月 11 04:27 ceph.log-20170411.gz
-rw------- 1 root root 63911 4月 13 09:24 ceph.log-20170413.gz
-rw-r--r-- 1 root root 0 4月 13 09:28 ceph-mds.vmnode1.log
-rw-r--r-- 1 root root 727 4月 11 04:27 ceph-mds.vmnode1.log-20170411.gz
-rw-r--r-- 1 root root 5446 4月 13 08:37 ceph-mds.vmnode1.log-20170413.gz
-rw-r--r-- 1 root root 888 4月 13 09:33 ceph-mon.vmnode1.log
-rw-r--r-- 1 root root 3520 4月 11 04:27 ceph-mon.vmnode1.log-20170411.gz
-rw-r--r-- 1 root root 38353 4月 13 09:27 ceph-mon.vmnode1.log-20170413.gz
-rw-r--r-- 1 root root 0 4月 13 09:28 ceph-osd.0.log
-rw-r--r-- 1 root root 528 4月 11 04:12 ceph-osd.0.log-20170411.gz
-rw-r--r-- 1 root root 164041 4月 13 09:13 ceph-osd.0.log-20170413.gz
-rw-r--r-- 1 root root 50865 4月 13 09:13 ceph-osd.3.log
......
为了方便管理您可以使用我们在之前专题介绍的Apache Flume对日志文件信息进行转移和汇总,以便于在一个固定的管理节点上查看所有节点的日志信息。Ceph文件系统还提供了一个系列用来即时反应文件系统内部变化,并输出到终端屏幕的命令:
-w, --watch watch live cluster changes
--watch-debug watch debug events
--watch-info watch info events
--watch-sec watch security events
--watch-warn watch warn events
--watch-error watch error events
// 使用示例为:
[root@vmnode2 ~]# ceph -w
// 实际上我们之前介绍的ceph -s命令,算是它的一个简化版本
[root@vmnode2 ~]# ceph -s
最后建议在检查/排查Ceph文件系统问题时,第一步就是使用ceph -w命令检视当前Ceph文件系统的活动变化情况。
3-2-3. 关于重新安装
安装Ceph文件系统的过程,特别是第一次安装Ceph文件系统的过程,绝对不会顺利。笔者最悲催的经历是连续搞了三次,整整花了2天时间,才把一个10节点的Ceph文件系统部署成功(最后总结发现是多种常见问题叠加导致的后果)。一旦出现问题,又长时间的无法解决,那么最暴力的办法就是回到第一步,重新安装整个Ceph文件系统。
好消息是ceph-deploy为我们提供了简便的命令,清除整个Ceph系统上所有节点的安装痕迹,恢复节点到初始状态:
// 以下命令清除指定节点上的ceph相关组件,类似于运行yum remove ceph ....
[root@vmnode1 ~]# ceph-deploy purge {ceph-node} [{ceph-node}]
// 命令示例为:
[root@vmnode1 ~]# ceph-deploy purge vmnode1 vmnode2 vmnode3
// 以下命令清除指定节点上ceph的相关目录、文件信息
// 类似于运行 rm -rf /home/ceph/* /etc/ceph/ ......
[root@vmnode1 ~]# ceph-deploy purgedata {ceph-node} [{ceph-node}]
// 命令示例为:
[root@vmnode1 ~]# ceph-deploy purgedata vmnode1 vmnode2 vmnode3
注意,ceph-deploy属于“安装助手”性质,所以ceph-deploy本身没有必要也删除掉。
3-3. Ceph常用命令
Ceph文件系统提供的运维命令主要是按照Ceph中的工作角色/工作职责进行划分的,例如有一套专门对OSD节点进行管理的命令、有一套专门对PG进行管理的命令、有一套专门对MDS角色进行管理的命令……您可以使用ceph –help进行命令列表的查看,本文我们对常用的命令进行描述,这些命令只是Ceph文件系统中的一部分命令,目的是保证在Ceph运行到生产环境后,您有能力定位常见问题,保证Ceph能够正常工作。
这里说明一下,ceph-deploy中的命令主要进行Ceph中各角色的安装、删除。所以对Ceph文件系统的日常维护还是不建议使用ceph-deploy中的命令,而建议尽可能使用Ceph文件系统的原生命令。
而ceph-deploy中的命令只建议在增加、删除节点/角色时使用。另外请注意,以下提到的新增、删除各种Ceph中角色的命令,也不建议在Ceph文件系统有大量I/O操作时进行,毕竟保证线上系统稳定,才是运维工作的重中之重。您可以选择Ceph系统相对空闲的时间进行这些操作,例如凌晨就是一个很好时间选择(加班狗赐予你力量)。
3-3-1. 集群管理相关命令
Ceph文件系统一旦通过ceph-deploy安装成功,在每一个成功安装的节点上Ceph都会作为Linux操作系统的服务被注册,所以要启动Ceph文件系统无非就是启动每个节点上的ceph服务。另外Ceph节点上运行的各种角色,除了MON角色默认会使用6789端口外,其它角色也会使用大量的网络端口,请保证这些网络端口没有被防火墙屏蔽。以下是某个Ceph节点上运行的各种角色所使用的网络端口示例(您和示例中的情况不一定完全一致):
......
tcp 0 0 0.0.0.0:6807 0.0.0.0:* LISTEN 9135/ceph-osd
tcp 0 0 0.0.0.0:6808 0.0.0.0:* LISTEN 9135/ceph-osd
tcp 0 0 0.0.0.0:6809 0.0.0.0:* LISTEN 9135/ceph-osd
tcp 0 0 0.0.0.0:6810 0.0.0.0:* LISTEN 9135/ceph-osd
tcp 0 0 0.0.0.0:6811 0.0.0.0:* LISTEN 9281/ceph-mds
tcp 0 0 172.16.71.187:6789 0.0.0.0:* LISTEN 8724/ceph-mon
tcp 0 0 0.0.0.0:6800 0.0.0.0:* LISTEN 8887/ceph-osd
tcp 0 0 0.0.0.0:6804 0.0.0.0:* LISTEN 8887/ceph-osd
tcp 0 0 0.0.0.0:6805 0.0.0.0:* LISTEN 8887/ceph-osd
tcp 0 0 0.0.0.0:6806 0.0.0.0:* LISTEN 8887/ceph-osd
......

启动MON、MDS、OSD
你可以通过以下命令启动当前节点下的Ceph角色(前提是您在这个节点下安装/配置了相应角色)
// 启动mon角色
[root@vmnode1 ~]# service ceph start mon.vmnode1
// 启动msd角色
[root@vmnode1 ~]# service ceph start mds.vmnode1
// 启动osd角色
[root@vmnode1 ~]# service ceph start osd.0
注意启动节点上的OSD角色时,后缀携带的并不是节点的名字,而是一个数字编号,例如以上示例中携带的数字编号就是“0”。这是因为一个操作系统节点可以携带若干个OSD角色,每个Ceph文件系统的OSD角色都有一个唯一的编号信息(编号数字从0开始),这个信息存放于OSD角色挂载的磁盘分区的根目录中,文件名为“whoami”。
例如osd.4角色挂载的分区根目录为 /usr/cephdata2,观察这个目录下的“whoami”文件,显示信息如下:
[root@vmnode2 ~]# cat /usr/cephdata2/whoami
4
停止MDS、MON、OSD
有启动当然就有停止,您可以通过以下命令停止某个节点上OSD角色、MDS角色或者MON角色的运行,或者干脆停止这个节点上所有正在运行的Ceph文件系统的角色:
// 停止mon角色
[root@vmnode1 ~]# service ceph stop mon.vmnode1
// 停止msd角色
[root@vmnode1 ~]# service ceph stop mds.vmnode1
// 停止osd角色
[root@vmnode1 ~]# service ceph stop osd.0
// 或者干脆全部停止
[root@vmnode1 ~]# service ceph stop
查看集群状态
涉及到这个功能的多个命令已经进行过说明,这里再次对这个命令列出,不再赘述这几个命令的具体不同:
// ceph集群状态概要
[root@vmnode1 ~]# ceph -s
// ceph集群事件变化实时监控
[root@vmnode1 ~]# ceph -w
查看集群空间使用情况
以下命令可以查看Ceph文件系统的空间使用情况:
[root@vmnode1 ~]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
XXXXX XXXXX XXXXX XXXXX
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 XXX XX XXX XXX
cephfs_data 1 XXX XX XXX XXX
cephfs_metadata 2 XXX XX XXX XXX
Ceph文件系统的构成单元是OSD Pool,创建一个文件系统需要两个OSD Pool,一个用于存储真实的数据(data pool),另一个用于存储元数据(metadata pool),那么很明显Ceph文件系统就支持多个OSD Pool存在。另外,每个OSD Pool都基于 OSD PG存储数据,OSD PG的工作方式会在后文进行说明。这就是为什么使用以上命令,看到的会是Ceph文件系统中已有的OSD Pool列表,以及每个OSD Pool的空间使用情况。
另外您还可以使用以下命令,查看Ceph文件系统绑定OSD Pool的情况:
[root@vmnode1 ~]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
以上命令反馈中,可以看到文件系统的名字为cephfs,用于记录文件系统元数据的OSD Pool名叫cephfs_metadata,用于记录文件系统真实数据的OSD Pool名叫 cephfs_data。
清除整个Ceph集群
这组命令也是在之前的文章中介绍过的,这里只列出命令示例:
// 清除已安装ceph组件的节点,类似于运行yum remove ceph....
[root@vmnode1 ~]# ceph-deploy purge vmnode1 vmnode2
// 命令格式为
ceph-deploy purge {ceph-node} [{ceph-node}]
// 清楚节点上和ceph相关的数据、配置信息
[root@vmnode1 ~]# ceph-deploy purgedata vmnode1 vmnode2
// 命令格式为
ceph-deploy purgedata {ceph-node} [{ceph-node}]
3-3-2. MON角色相关命令
添加或删除一个MON角色(使用ceph-deploy)
// 创建一个新的mon节点
[ceph@vmnode1 ~]$ ceph-deploy mon create newnode
// 删除一个mon角色
[ceph@vmnode1 ~]$ ceph-deploy mon destroy vmnode3
// 命令格式为
ceph-deploy mon [-h] {add,create,create-initial,destroy} ...
create-initial参数的意义就不用多说了,初始化整个Ceph文件系统的MON角色,在上一篇介绍Ceph文件系统的安装过程中,我们第一次初始化整个Ceph文件系统的MON角色时,就是用的是create-initial参数。这里请注意add参数和create参数的不同意义,如果将要加入Ceph文件系统的MON节点还没有MON服务角色的配置信息,那么使用create参数(多数情况下是这样)。如果将要加入Ceph文件系统的MON节点上已经有了MON角色的配置,只是没有加入到Ceph系统中,则使用add参数。
查看MON角色状态/选举情况
// 查看MON角色状态
[ceph@vmnode1 ~]$ sudo ceph quorum_status --format json
e2: 2 mons at {vmnode1=172.16.71.186:6789/0,vmnode3=172.16.71.185:6789/0}, election epoch 186, quorum 0,1 vmnode3,vmnode1
// 查看MON角色选举状态
[ceph@vmnode1 ~]$ sudo ceph quorum_status --format json
{
"election_epoch": 186,
"quorum": [
0,
1
],
"quorum_names": [
"vmnode3",
"vmnode1"
],
"quorum_leader_name": "vmnode3",
"monmap": {
"epoch": 2,
"fsid": "f470130e-93c8-4280-8ad6-e5331207451f",
"modified": "XXXXXXXXXXXXX",
"created": "0.000000",
"mons": [
{
"rank": 0,
"name": "vmnode3",
"addr": "172.16.71.185:6789\/0"
},
{
"rank": 1,
"name": "vmnode1",
"addr": "172.16.71.186:6789\/0"
}
]
}
}
MON角色采用主备模式(leader/follower),也就是说即使系统中有多个MON角色,实际工作的也只有一个MON角色,其它MON角色都处于standby状态。当Ceph系统中失去了Leader MON后,其它MON角色会基于PaxOS算法,投票选出新的Leader MON。既然是这样,那么类似以上示例结果中显示MON节点只有两个的情况,就不再允许Leader MON角色退出了,因为一旦退出,投票决议始终都无法达到参与者的 N / 2 1的多数派,也就始终无法选出新的Leader MON(关于PaxOS算法的详细讲解请参看我另外几篇博客文章《系统存储(23)——数据一致性与Paxos算法(上)》、《系统存储(24)——数据一致性与Paxos算法(中)》、《系统存储(25)——数据一致性与Paxos算法(下)》)。而要保证MON角色的持续可用性,就至少需要在Ceph文件系统中,保持三个MON角色节点(这样可以允许最多一个MON角色节点错误离线)。
理解了Leader MON的选举方式,就可以理解以上示例中显示的MON选举状态信息了:quorum_names和quorum 是指代的投票参与者和投票参与者的编号、quorum_leader_name表示当前选举出来的Leader MON,election_epoch代表目前一共经历的投票轮次数量,epoch代表发起投票的次数(一次投票发起后,可能需要多轮投票才能选出新的Leader MON角色);而monmap中除了Ceph文件系统的基本信息外,还有一个rank属性,代表了每个MON角色的权重,权重越小的MON角色,在投票选举中越容易获得多数派支持。最后MON角色中可不只是存储了monmap信息,我们在后文介绍Ceph工作过程时,还会详细讲解。
3-3-3. MDS角色相关命令
添加一个MDS角色(使用ceph-deploy)
可以使用以下命令格式进行MDS的添加
[ceph@vmonde1 ~]# ceph-deploy mds create {hostname}
#例如:
[ceph@vmonde1 ~]# ceph-deploy mds create vmnode4
查看MDS角色状态
请注意一个操作系统节点只能添加一个MDS角色,而不能像添加OSD节点那样:只要有多余的磁盘分区进行独立挂载就可以在一个操作系统节点上添加多个OSD角色。另外Ceph文件系统中的多个MDS角色也是采用主备模式工作,而主备状态的决定、监控和切换完全由MON角色来控制。所以,如果您的Ceph文件系统中有多个MDS角色,并且运行查看MDS角色状态的命令,就会看到类似以下的查询结果:
[root@vmonde1 ~]# ceph mds stat
e48: 1/1/1 up {0=vmnode3=up:active}, 2 up:standby
从以上的执行结果来看,vmnode3节点上的MDS角色处于活动状态,另外两个节点上的MDS角色处于“待命”状态,您还可以使用以下命令,查看更详细的mds角色的工作状态。
[root@vmnode1 ~]# ceph mds dump
......
epoch 48
flags 0
created 2017-04-XX XXXXXX
modified 2017-04-XX XXXXXXX
......
删除一个MDS角色
使用以下命令,可以删除某个节点上的MDS角色
ceph mds rm gid(<int[0-]>) <name (type.id)>
#例如:
[root@vmnode1 ~]# ceph mds rm 0 mds.vmnode1
3-3-4. OSD角色相关命令
上文已经提到,可以通过以下命令在OSD挂载的根路径查看当前OSD角色的编号,如下所示:
[root@vmnode2 ~]# cat /usr/cephdata2/whoami
4
说明这个挂载点对应的OSD角色编号为4,我们将在维护OSD角色的命令中会使用这个编号,例如在OSD角色的停止/删除命令中。
删除一个OSD角色
// 以下命令停止一个OSD角色的运行,但是并不将其排除到Ceph文件系统之外
[root@vmnode1 ~]# ceph osd down 0
// 以下命令将指定的OSD角色移除Ceph文件系统
[root@vmnode1 ~]# ceph osd rm 0
// 以下命令可以将指定节点上所有的OSD角色全部移除
[root@vmnode1 ~]# ceph osd crush rm vmnode1
以上命令中的参数“0”,代表OSD节点的的编号。另外需要注意,如果需要将指定的OSD角色从Ceph文件系统中移除,那么首先需要停止这个节点(运行之上的osd down命令,或者直接关闭OSD服务都行),否则Ceph文件系统会报类似如下的错误:
[root@vmnode1 ~]# ceph osd rm 0
Error EBUSY: osd.0 is still up; must be down before removal.
添加一个OSD角色(使用ceph-deploy)
使用ceph-deploy时,通过以下命令可以初始化一个OSD角色,并加入到Ceph文件系统中
// 初始化一个OSD角色
[root@vmnode1 ~]# ceph-deploy osd prepare vmnode4:/fs/osdroot
// 命令格式为
// ceph-deploy osd prepare {ceph-node}:{/path/to/directory}
// 启动这个新的OSD角色
[root@vmnode1 ~]# ceph-deploy osd activate vmnode4:/fs/osdroot
// 命令格式为
// ceph-deploy osd activate {ceph-node}:{/path/to/directory}
以上命令中,ceph-node是指节点名,后续的目录是指这个新的OSD角色所挂载的磁盘分区的根目录。在完成OSD角色初始化后,就会在OSD使用的目录挂载点根部出现准备好的若干目录和文件信息,例如本文之前提到的whoami文件,就是这个时候产生的。除了ceph-deploy osd activate可以启动一个这个新的OSD角色外,Ceph文件系统自生也提供OSD角色初始化启动的命令,如下所示:
[root@vmnode1 ~]# ceph-disk -v activate --mark-init sysvinit --mount /fs/osdroot/
查看OSD角色状态
// 以下命令可以查看Ceph文件系统中OSD角色的概要状态信息
[root@vmnode1 ~]# ceph osd stat
osdmap e127: 6 osds: 6 up, 6 in
// 如果想查看更详细的状态信息,可以使用以下命令
[root@vmnode1 ~]# ceph osd dump
epoch 127
fsid f470130e-93c8-4280-8ad6-e5331207451f
created 2017-04-XX XXXXXXXX
modified 2017-04-XX XXXXXXXXXX
......
查看OSD角色位置结构
由于Ceph文件系统中,允许一个操作系统节点下添加多个OSD角色,当Ceph文件系统中的节点数量还不多时,技术人员还记得清楚OSD角色和节点的对应关系,但是当Ceph文件系统中的节点数到了一定的数量级后,技术人员就不一定能全记住。Ceph文件系统中提供给技术人员记录这些OSD存在位置的命令:
[root@vmnode1 ~]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0 root default
-2 0 host vmnode1
0 0 osd.0 up 1.00000 1.00000
3 0 osd.3 up 1.00000 1.00000
-3 0 host vmnode2
1 0 osd.1 up 1.00000 1.00000
4 0 osd.4 up 1.00000 1.00000
-4 0 host vmnode3
2 0 osd.2 up 1.00000 1.00000
5 0 osd.5 up 1.00000 1.00000
......
更改OSD角色权重
以上命令中所列出的各个列都很好理解,其中有一列名叫REWEIGHT,是指的每个OSD角色的权重值。OSD角色的权重值将会对存储数据的位置产生影响。通过以下命令,技术人员可以更改某个OSD角色的权重,命令如下(注意:以下命令中WEIGHT的值只能设定在0.0到1.0之间。):
[root@ceph-manager ~]# ceph osd reweight 1 0.9
// 命令格式为
ceph osd reweight {OSD.ID} {WEIGHT}
————————————————
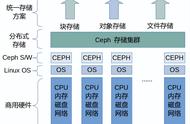
4. Ceph顶层架构总览
此图来源于官网,很多网络上的资料也引用了这张图,但是并没有讲清楚出现在图中的和没有出现在图中的(但同样重要的)几个名词到底是什么含义,例如,RADOS、LIBRADOS、RADOSGW、RDB、CEPH FS、MON、OSD、MDS等等。读者要搞清楚Ceph的顶层架构,就首先要搞清楚这些名词代表的技术意义,以及这些技术的在Ceph顶层架构中所占据的地位。
4-1. 名词解释
请看以下这张图对Ceph顶层架构抽象名词的功能细化:

是不是这样看就要亲切多了。实际上我们一直讲的Ceph分布式对象存储系统只是上图中的RADOS部分(Reliable Autonomic Distributed Object Store),其中就包括了MON和OSD两大角色。至于MON和OSD中又包括了什么,本文后续将进行介绍。
这里要特别说明以下,请注意上图中MDS角色所在位置。我们先来回想一下在前文介绍Ceph文件系统安装的时候,当我们还没有创建MDS角色时,查看Ceph的状态同样可以看到“HEALTH_OK”的提示信息,如下所示:
[ceph@vmnode1 ~]$ sudo ceph -w
cluster d05f71b6-0d52-4cde-a010-582f410eb84d
health HEALTH_OK
monmap e1: 3 mons at {......}
election epoch 6, quorum 0,1,2 vmnode1,vmnode2,vmnode3
osdmap e13: 3 osds: 3 up, 3 in
pgmap v19: 64 pgs, 1 pools, 0 bytes data, 0 objects
15458 MB used, 584 GB / 599 GB avail
64 active clean
只是这时我们还看不到mdsmap的信息,也就是说MDS角色并不是Ceph文件系统RADOS核心部分的必备元素。实际上MDS角色是专门为Ceph FS子系统服务的角色,其上记录了元数据信息说明了Ceph FS子系统中文件目录、文件路径和OSD PG的对应关系。所以当我们创建MDS角色,并使用以下命令创建了Ceph FS文件系统后,才能看到Ceph文件系统上的MDS角色信息,如下所示:
[ceph@vmnode1 ~]$ sudo ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
[ceph@vmnode1 ~]$ sudo ceph mds stat
e7: 1/1/1 up {0=vmnode2=up:active}, 2 up:standby
[ceph@vmnode1 ~]$ sudo ceph -s
cluster d05f71b6-0d52-4cde-a010-582f410eb84d
health HEALTH_OK
monmap e1: 3 mons at {......}
election epoch 6, quorum 0,1,2 vmnode1,vmnode2,vmnode3
mdsmap e7: 1/1/1 up {0=vmnode2=up:active}, 2 up:standby
osdmap e18: 3 osds: 3 up, 3 in
pgmap v32: 128 pgs, 3 pools, 1962 bytes data, 20 objects
15459 MB used, 584 GB / 599 GB avail
128 active clean
client io 2484 B/s wr, 9 op/s
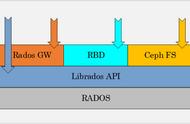
RADOS之上有一个访问协议层,任何对分布式对象存储系统(RADOS)进行读写的各类型客户端,都需要通过这个访问协议层来完成操作。而这个访问协议层的具体体现就是编程语言库称为LIBRADOS,如果您使用Ceph-deploy安装助理进行Ceph文件系统的部署的话,那么LIBRADOS在部署RADOS的同时就安装好了,默认是C 版本的。您也可以独立安装其它版本的LIBRADOS,例如Python版本或者Java版本。以下命令可以安装访问协议层对Java语言的支持库:
yum install jna
// 安装好以后相关的jar文件默认存放在/usr/share/java目录下
至此技术人员就可以使用LIBRADOS直接操作RADOS中的MON、OSD角色了。但问题是,这样的调用方式并不适用于各种类型的客户端,因为毕竟只是一套访问协议层的具体实现代码。为了便于需要使用Ceph文件系统的各种客户端,在各类情况下都能进行简便的操作,Ceph官方还建立了多种子项目,产生了建立在LIBRADOS之上的多种访问方式。
CEPH FS就是我们最熟悉的一个子项目,它的目的是基于LIBRADOS,遵循POSIX规范提供给各种Linux操作系统将Ceph文件系统作为本地文件系统进行挂载使用的能力,同时也提供对FUSE的支持。
RADOSGW的全称是RADOS Gateway,中文名Ceph对象网关。客户端可以通过它,使用HTTP restful形态的结构访问RADOS。官网上对它的解释是:
RADOSGW is an HTTP REST gateway for the RADOS object store, a part of the Ceph distributed storage system. It is implemented as a FastCGI module using libfcgi, and can be used in conjunction with any FastCGI capable web server.
那么RDB又是什么呢?RDB全称RADOS Block Devices,初看名字就和块存储有一定关系。是的,这是基于RADOS建立的块存储软件设备。那么我们要回答的一个问题是,为什么需要把一个分布式对象存储系统通过RDB向上模拟成一个块存储设备呢?这是因为需要对诸如KVM这样的客户端访问提供支持。
举一个浅显易懂的例子,VMware的虚拟机产品相信大家都用过,VMware在创建一个虚拟机时需要设置这台虚拟机的CPU数量、内存数量等内容,而设置的存储设备时都必须是基于块存储技术的设备,例如一个物理磁盘分区、一个真实存在的光驱设备等。如果要让虚拟机能够使用Ceph文件系统,就必须在上层将Ceph文件系统模拟成一个块存储设备。实际上Ceph文件系统上层的RDB子项目,是OpenStack生态中能够集成Ceph文件系统的基本条件。Glance或者Cinder本质上是将Ceph文件系统看成和NAS一样的块存储设备并将其集成进来。
4-2. RADOS结构
关于RADOS上层的访问协议层功能,以及之上的各种子项目的介绍本文只是点到为止,相关的知识点就不再做扩展讲解了。既然Ceph分布对象存储系统中最重要的就是RADOS部分,那么我们还是要将介绍的重点收回来。

4-3. 数据存储到RADOS的过程
那么一个文件从请求进入Ceph RADOS到最终存储下来的过程过程中,到底发生了什么?这里我们直接通过原生命令操作RADOS,来测试一下这个过程:
[root@vmnode1 ~]# echo "yinwenjie ceph test info" > file
[root@vmnode1 ~]# rados put ceph-object1 ./file --pool=cephfs_data
我们直接通过RADOS进行操作,就可以避免RADOS上层各个子系统对我们分析问题造成的影响。首先第一条命令我们给一个名为“file”的文件取了一个对象名,对象名为ceph-object1,并使用一个名叫datapool的OSD Pool保存这个对象。请注意这里有一个曾经解释过的概念,即OSD Pool是存在于多个OSD上PG块的集合,它是Ceph文件系统中存储对若干Object信息的管理单元。
在这个命令之下RADOS完成了几件事情:
首先RADOS会将这个文件转换成一个或者多个Object。每个Object的最大大小是有限制的,默认为4MB,所以如果文件太大,就会拆分为多个Object。每个Object信息中有几个重要属性,例如oid表示这个object在Ceph文件系统中的唯一编号、name表示Object的唯一名字、snapshot快照信息、以确定的所在pool的对应关系等等。通过以下命令,我们可以查看到保存在OSD Pool中的那个对象:
[root@vmnode1 ~]# rados -p cephfs_data ls
......
ceph-object1
......
转换为Object就可以开始进行真正的存储了,存储Object信息的单元称为PG(Placement Group),每个PG可以存储很多Object信息。并且PG还可以分为Primary PG和Replicas PG。例如上图编号为PG1的PG块就有三个,分别存放在三个不同的OSD角色中,其中灰色底的PG1是Primary PG,另外两个是Replicas PG。也就是说这个OSD Pool中的PG副本数量为3。
我们在创建OSD Pool时,需要初始化指定这个OSD Pool的PG数量,这里有一个官方推荐的公式,可以帮助读者确定这个初始的PG数量怎么设置才合理:
Total PGs = ((Total_number_of_OSD * 100) / max_replication_count) / pool_count
其中 Total_number_of_OSD 表示目前Ceph文件系统中OSD角色的个数,max_replication_count表示设置的最大副本数量,pool_count表示计划设定的Ceph文件系统中的总的pool数量。举个例子来说,当Ceph文件系统中OSD角色的数量为20、最大副本数量为3、计划设定的Pool数量为3时,带入公式就可以得到PG数量应设定为222。但是关于PG的设定还有一个建议,就是建议设定为2的N次方,那么离222最近的数值就是256.Pool中PG的数量是可以调整,但是Ceph文件系统只允许调大PG的数量,不允许调减——原因很简单,因为这些PG已经存储信息了。并且调整前,最好向Ceph文件系统中加入新的OSD角色,否则调整意义就不大。
那么Ceph文件系统是怎么确定和一个Object存放到哪个PG上的呢?首先Ceph知道Pool中总的PG数量,也知道当前Object的oid编号。那么这个问题使用一致性Hash算法就很好解决了——基于Objec的oid进行Hash计算。我们可以通过以下命令,查看某个Object所在的PG位置;
[root@vmnode1 ~]# ceph osd map cephfs_data ceph-object1
osdmap e18 pool 'cephfs_data' (1) object 'ceph-object1' -> pg 1.adfc9c54 (1.14) -> up ([1,2], p1) acting([1,2], p1)
在之前的文章中我们已经提到过,Ceph文件系统中最终落地存储的角色是OSD(对象存储设备),也就是说在确定Object和PG的对应关系后,还需要确定PG和OSD的对应关系,这个过程所需要考虑的因素就比在确认Object和OSD的对应关系是考虑的因素多得多了,例如承载OSD角色的物理节点其性能可能不一样,在确定承载PG的OSD时不仅要考虑散列度,还需要考虑节点的性能问题;再例如多个OSD角色可能存在于同一个物理节点上(这个特点在之前的文章中有过说明),那么相同PG的Primary PG和Replicas PG最好就不要放在同一个物理节点上,以免当物理节点崩溃后,相同PG的多个副本一起失效;再举一个例子,为了保证副本间的同步性能,最好将存储相同PG的多个副本落地在同一个机架上,或者同一个子网内,或者同一个机房内,这样可以尽可能的降低网络延迟。
显然要考虑这么多因素,肯定不是简单使用一致性Hash算法就能解决的,所以Ceph文件系统中专门有一个CRUSH算法来完成这个工作。相对于一致性Hash算法,CRUSH算法是考虑的多种因素的动态算法,只要Ceph文件系统的状态发生变化,CRUSH算法的计算结果就会不一样。例如当Ceph文件系统中某个物理节点失效时,当新的OSD节点加入并开始承载新的PG时。
通过以下命令,可以查看目前Ceph文件系统中CRUSH算法算法的装载状态:
[root@vmnode1 ~]# ceph osd crush dump
{
"devices": [
{
"id": 0,
"name": "osd.0"
},
......
],
"types": [
......
{
"type_id": 2,
"name": "chassis"
},
{
"type_id": 3,
"name": "rack"
},
......
],
"buckets": [
......
{
"id": -2,
"name": "vmnode1",
"type_id": 1,
"type_name": "host",
"weight": 13107,
"alg": "straw",
"hash": "rjenkins1",
"items": [
{
"id": 0,
"weight": 13107,
"pos": 0
}
]
},
......
],
"rules": [
{
"rule_id": 0,
"rule_name": "replicated_ruleset",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
......
]
}
],
"tunables": {
"choose_local_tries": 0,
"choose_local_fallback_tries": 0,
.......
"has_v2_rules": 0,
"has_v3_rules": 0,
"has_v4_buckets": 0
}
}
————————————————
版权声明:本文为CSDN博主「说好不能打脸」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yinwenjie/article/details/70379479
,