由于最近一直在鼓捣存储这一块,所以今天主要是分析一下我们可爱的ceph的工作原理,方便大家进一步掌握ceph的主要工作流程,对后期使用ceph有很大帮助.
一、简介
Ceph是一个分布式存储系统,诞生于2004年,最早致力于开发下一代高性能分布式文件系统的项目。随着云计算的发展,ceph乘上了openstack的春风,进而成为了开元社区受到关注度非常高的项目之一。
Ceph优势:
1.CRUSH算法
Crush算法是ceph的两大创新之一,简单来说,ceph丢掉了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作,该算法在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本防止规则,例如跨机房、机架感知等。Crush算法有相当大的扩展性,理论上支持数千存储节点。
2.高可用
Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以及分割故障域,支持数据强一致性;ceph可以忍受多种故障场景并自动尝试并行修复。
3.高扩展性
Ceph不同与swift,客户端所有的读写操作都要经过代理节点。一旦集群并发量增大时,代理节点很容易成为单点瓶颈。Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,他的性能回随着数量的增加而线性增长。
4.特性丰富
Ceph支持三种调用接口:对象存储,块存储,文件系统挂在。三种方式可以一同使用。在国内一些公司的云环境中,通常会用ceph作为openstack的唯一后端存储来提升数据转发效率。
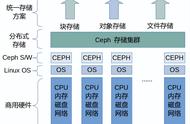
二、CEPH的基本结构
Ceph的基本组成结构如下图:

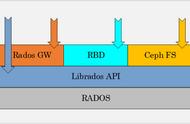
Ceph的底层是RADOS,RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现的。RADOS采用C 开发,所提供的原生Librados API包括C和C 两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作.
RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW是一个提供与Amazon S3和Swift兼容的RESful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下虚拟机创建volume。目前,Rad Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
CEPHFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所以无需调用用户空间的librados库。它通过内核的net模块来与Rados进行交互
三、Ceph的基本组件

如上图所示,Ceph主要有三个基本进程
- Osd
- 用于集群中所有数据与对象的存储。处理集群数据的复制、恢复、回填、再均衡。并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。
- 当Ceph存储集群设定数据有两个副本时(一共存两份),则至少需要两个OSD守护进程即两个OSD节点,集群才能达到active clean状态。
- MDS(可选)
- 为Ceph文件系统提供元数据计算、缓存与同步。在ceph中,元数据也是存储在osd节点中的,mds类似于元数据的代理缓存服务器。MDS进程并不是必须的进程,只有需要使用CEPHFS时,才需要配置MDS节点。
- Monitor
- 监控整个集群的状态,维护集群的cluster MAP二进制表,保证集群数据的一致性。ClusterMAP描述了对象块存储的物理位置,以及一个将设备聚合到物理位置的桶列表。
四、OSD
首先描述一下ceph数据的存储过程,如下图: