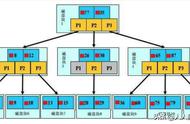
所以当使用where ID = 7这样的条件查找主键,则按照B 树的检索算法即可查找到对应的叶节点,之后获得行数据。对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B 树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主键索引B 树种再执行一次B 树检索操作,最终到达叶子节点即可获取整行数据。
最后把以上过程整理总结一下,聚簇索引实际上的过程就分为以下两个过程。现在这个图应该能够看懂了吧。

非聚簇索引
学完了聚簇索引,非聚簇索引就简单多啦。同样,先上定义。
非聚簇索引的主键索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点都存储指向键值对应的数据的物理地址。
与聚簇索引来对比着看,上面的定义能够说明什么呢。首先,主键索引和辅助索引的叶子结点都存储着键值对应的数据的物理地址,这说明无论是主键索引还是辅助索引都能够通过直接获得数据,而不需要像聚簇索引那样在检索辅助索引时还得多绕一圈。
同时还说明一个点,叶子结点存储的是物理地址,那么表示数据实际上是存在另一个地方的,并不是存储在B 树的结点中。这说明非聚簇索引的数据表和索引表是分开存储的。
同样,对非聚簇索引的检索过程来个总结。

无论是主键索引还是辅助索引的检索过程,都只需要通过相应的 B Tree 进行搜索即可获得数据对应的物理地址,然后经过依次磁盘 I/O 就可访问数据。
对比聚簇索引和非聚簇索引,可以发现二者最主要的区别就是在于是否在 B Tree 的节点中存储数据,也就是数据和索引是否存储在一起。这个区别导致最大的问题就是聚簇索引的索引的顺序和数据本身的顺序是相同的,而非聚簇索引的顺序跟数据的顺序没有啥关系。

介绍了这么多的索引,其实最终都是为了建立高性能的索引策略,对数据库中的索引进行优化。索引的优化有很多角度,针对特定的业务场景可采用不同的优化策略。这里考虑到文章篇幅,就不具体介绍,下次再出一篇专门讲索引优化的文章。简单列举一下在进行优化时可以考虑的几个方向:
1 独立的列。索引列不能是表达式的一部分,也不能是函数的参数。
2 前缀索引和索引选择性。这二者实际上是相互制约的关系,制约条件在于前缀的长度。一般应选择足够长的前缀以保证较高的选择性(保证查询效率),同时又不能太长以便节省空间。
3 尽量使用覆盖索引。覆盖索引是指一个索引包含所有需要查询的字段的值,这样在查询时只需要扫描索引而无须再去读取数据行,从而极大的提高性能。
4 使用索引扫描来做排序。要知道,扫描索引本身是很快的,在设计索引时,可尽可能的使用同一个索引既满足排序,又满足查找行数据。
最后,在建立索引时给几个小贴士:
1 优先使用自增key作为主键
2 记住最左前缀匹配原则
3 索引列不能参与计算
4 选择区分度高的列作索引
5 能扩展就不要新建索引