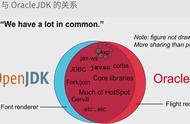
可以看到已经是使用的OpenJDK
5
组件功能校验
1.Kerberos环境下提交MapReduce作业
[root@ip-172-31-6-83 java]# kinit fayson JAR does not exist or is not a normal file: /opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop-0.20-mapreduce/hadoop-examples.jar [root@ip-172-31-6-83 java]# klist Ticket cache: FILE:/tmp/krb5cc_0 Default principal: fayson@FAYSON.COM Valid starting Expires Service principal 12/29/2018 21:37:16 12/30/2018 21:37:16 krbtgt/FAYSON.COM@FAYSON.COM renew until 01/05/2019 21:37:16 [root@ip-172-31-6-83 java]# hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 1

作业执行成功

2.运行Hive作业
[root@ip-172-31-6-83 java]# beeline WARNING: Use "yarn jar" to launch YARN applications. slf4j: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Beeline version 2.1.1-cdh6.1.0 by Apache Hive beeline> !connect jdbc:hive2://localhost:10000/;principal=hive/ip-172-31-6-83.ap-southeast-1.compute.internal@FAYSON.COM Connecting to jdbc:hive2://localhost:10000/;principal=hive/ip-172-31-6-83.ap-southeast-1.compute.internal@FAYSON.COM Connected to: Apache Hive (version 2.1.1-cdh6.1.0) Driver: Hive JDBC (version 2.1.1-cdh6.1.0) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000/> show tables; INFO : Compiling command(queryId=hive_20181229214127_90e75174-6be5-4579-bd84-b4f336a7fe94): show tables INFO : Semantic Analysis Completed INFO : Returning Hive Schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=hive_20181229214127_90e75174-6be5-4579-bd84-b4f336a7fe94); Time taken: 1.189 seconds INFO : Executing command(queryId=hive_20181229214127_90e75174-6be5-4579-bd84-b4f336a7fe94): show tables INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=hive_20181229214127_90e75174-6be5-4579-bd84-b4f336a7fe94); Time taken: 0.079 seconds INFO : OK ----------- | tab_name | ----------- | t1 | ----------- 1 row selected (2.031 seconds) 0: jdbc:hive2://localhost:10000/> select count(*) from test; Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'test' (state=42S02,code=10001) 0: jdbc:hive2://localhost:10000/> select count(*) from t1; INFO : Compiling command(queryId=hive_20181229214145_7e6b27e8-dac8-4529-85e0-ec3b6ce6c9c2): select count(*) from t1 INFO : Semantic Analysis Completed INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null) INFO : Completed compiling command(queryId=hive_20181229214145_7e6b27e8-dac8-4529-85e0-ec3b6ce6c9c2); Time taken: 0.445 seconds INFO : Executing command(queryId=hive_20181229214145_7e6b27e8-dac8-4529-85e0-ec3b6ce6c9c2): select count(*) from t1 WARN : INFO : Query ID = hive_20181229214145_7e6b27e8-dac8-4529-85e0-ec3b6ce6c9c2 INFO : Total jobs = 1 INFO : Launching Job 1 out of 1 INFO : Starting task [Stage-1:MAPRED] in serial mode INFO : number of reduce tasks determined at compile time: 1 INFO : In order to change the average load for a reducer (in bytes): INFO : set hive.exec.reducers.bytes.per.reducer=<number> INFO : In order to limit the maximum number of reducers: INFO : set hive.exec.reducers.max=<number> INFO : In order to set a constant number of reducers: INFO : set mapreduce.job.reduces=<number> INFO : number of splits:1 INFO : Submitting tokens for job: job_1546090332827_0002 INFO : Executing with tokens: [Kind: HDFS_DELEGATION_TOKEN, Service: 172.31.6.83:8020, Ident: (token for fayson: HDFS_DELEGATION_TOKEN owner=fayson, renewer=yarn, realUser=hive/ip-172-31-6-83.ap-southeast-1.compute.internal@FAYSON.COM, issueDate=1546090906263, maxDate=1546695706263, sequenceNumber=10, masterKeyId=5), Kind: HIVE_DELEGATION_TOKEN, Service: HiveServer2ImpersonationToken, Ident: 00 06 66 61 79 73 6f 6e 06 66 61 79 73 6f 6e 3e 68 69 76 65 2f 69 70 2d 31 37 32 2d 33 31 2d 36 2d 38 33 2e 61 70 2d 73 6f 75 74 68 65 61 73 74 2d 31 2e 63 6f 6d 70 75 74 65 2e 69 6e 74 65 72 6e 61 6c 40 46 41 59 53 4f 4e 2e 43 4f 4d 8a 01 67 fa 32 82 0e 8a 01 68 1e 3f 06 0e 01 01] INFO : The url to track the job: http://ip-172-31-6-83.ap-southeast-1.compute.internal:8088/proxy/application_1546090332827_0002/ INFO : Starting Job = job_1546090332827_0002, Tracking URL = http://ip-172-31-6-83.ap-southeast-1.compute.internal:8088/proxy/application_1546090332827_0002/ INFO : Kill Command = /opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/bin/hadoop job -kill job_1546090332827_0002 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 INFO : 2018-12-29 21:41:55,587 Stage-1 map = 0%, reduce = 0% INFO : 2018-12-29 21:42:03,810 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.91 sec INFO : 2018-12-29 21:42:09,965 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.35 sec INFO : MapReduce Total cumulative CPU time: 4 seconds 350 msec INFO : Ended Job = job_1546090332827_0002 INFO : MapReduce Jobs Launched: INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.35 sec HDFS Read: 7955 HDFS Write: 101 HDFS EC Read: 0 SUCCESS INFO : Total MapReduce CPU Time Spent: 4 seconds 350 msec INFO : Completed executing command(queryId=hive_20181229214145_7e6b27e8-dac8-4529-85e0-ec3b6ce6c9c2); Time taken: 25.491 seconds INFO : OK ------ | _c0 | ------ | 1 | ------ 1 row selected (26.088 seconds)