处理器从缓存中读取数据的速度快于 RAM ,因此缓存的出现有助于我们节省时间。当处理器下达指令要内存处理器去访问某个内存地址时,内存处理器其实还把要访问地址的相邻地址的内容一起返回给处理器,处理器把这些内容存储在缓存中。
假如处理器想按顺序,先后访问地址 951、952、953、954 … 在第一次读取地址 951 时就会把所需的内容全部取出来放到处理器的缓存中,之后 952 、953、954 的读取则是通过快速的缓存读取方式获得。
但是假如处理器先后访问的地址是 951、321、146 … 那此时的缓存就帮不上忙了,内存管理器每次都得老老实实的去 RAM 区获取数据,当然速度就会比上面的慢了。
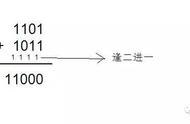
二进制表示数字
上面我们已经知道如何用二进制表示十进制,日常生活中使用的数字范围在在计算机中可以用 4 或 8 个字节(32 或 64 bit)来表示:
4 比特可以表示的数字范围:2147483648 ~ 2147483647
8 比特可以表示的数字范围:9223372036854775808 ~ 9223372036854775807
二进制还可以用来表示分数、小数、负数:
分数:分别储存两个数:分子和分母
小数:分别存储两个数:去掉小数点后的数字;小数点出现的位置
负数:二进制位中最左边的那一位代表符号,0 表示正数,1 表示负数;
二进制表示字符
了解了计算机如何用二进制表达数字(十进制),那么计算机如何用二进制表达字符呢?计算机用到了编码(encoding)。编码就是一套数字和字符间的映射关系,有许多不同的编码格式,举个常用的例子: ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)。ASCII 编码表可以翻译数字、大小写字母、以及常用的一些特殊符号,有了这套规则,计算机就知道如何应对我们输入的内容了:

假设我们输入的内容为 NICE ,通过 ASCII 编码表首先转化成十进制为:
78 73 67 69
再转成二进制:
01001110 01001001 01000011 01000101
观察上面这个例子发现
一个字符需要 8 bit 来表示,也就是 1 byte
二进制表示字母都以 0 开头
看起来只需要 7 bit 就能表达一个字符,第一个 bit 总是 0 ,给人的感觉好像是浪费了 1 bit,那么当初设计这个表的时候难道没发现这个 bug 么?再看一眼上面的 ASCII 表,我们发现表中缺了很多其他特殊符号,如 é、æ 等等,这些符号计算机要怎么用二进制表达呢?最初设计的 ASCII 编码表只用到了 7 bit ,因此有 128 种可能,再把第一位利用起来,ASCII 编码表就得以翻倍扩展。

还有其他方式可以对字符编码,例如 Unicode 编码表,可以用来表达世界上各个国家的字符,区别在于每个字符占用 2 个 byte(这样理论上一共最多可以表示 2的16次方(即 65536 )个字符。基本满足各种语言的使用。实际上当前版本的 Unicode 码并未完全使用这 16 位编码,而是保留了大量空间以作为特殊使用或将来扩展)。这些编码的核心思想是一致的:建立一套规则作为抽象层,用来简化我们在字符和二进制之间的转化方式。
近期文章:
Python之父再度为996发声,而我们呢?
Flutter 入门指北之常用布局
程序员写墓志铭……
今日问题:
你还记得二进制吗?

在码个蛋(codeegg)后台回复「社群」即可加入学习群