核心任务:
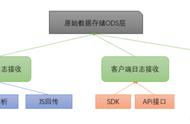
数据采集的核心任务包括请求获取数据和解析数据。
请求获取数据涉及发送HTTP请求以获取网站上的信息。
解析数据涉及将网站返回的信息解析为可用的数据格式。
Python工具:
Python是一种常用的数据采集工具,使用库如requests、lXML和JSON可以处理大多数简单的数据采集任务。
这些库可以帮助你发送HTTP请求、解析HTML或JSON数据,并进行数据清洗和转换。
重要技能:
理解网站结构、数据格式、HTTP请求和响应以及数据清洗是数据采集过程中的关键技能。
这些技能帮助你有效地定位和提取所需的数据。
初学者建议:
对于初学者,建议学习基本的编程和网络请求知识。
这将帮助你更好地理解数据采集过程,包括如何构建和发送HTTP请求,以及如何处理返回的数据。
相关挑战:
数据量与时间压力:需要采集大量数据,而且时间要求紧迫,可能需要优化代码以提高数据获取速度,采用并行处理或异步请求等技术来提高效率。
网站接口加密:一些网站会使用加密技术来保护其数据接口,可能需要破解或模拟解密这些接口,以获取数据。
风控和反爬虫:网站通常采用反爬虫机制来防止自动化数据采集。为了绕过这些机制,可能需要模拟人类用户行为、使用代理IP、调整请求频率或者随机化请求头信息。
数据格式多样性:数据可能以不同的格式呈现,包括HTML、JSON、XML等。你需要根据数据格式选择合适的解析方法,以提取所需信息。
返回数据加密:有些网站可能对返回的数据进行加密,需要使用相应的解密算法来处理数据。
这些观点整合了数据采集的核心任务和相关挑战,希望对你有所帮助。
,