高级图(上方)和低级图(下方)示例
在添加奖励之前,学习算法会在给出下列约束条件后找到最佳分层结构:
小型状态簇;
状态簇内的密集连接;
状态簇间的稀疏连接。
然而,我们不希望状态簇太小——在极端情况下,每个节点就是它自己的状态簇,这使得分层结构没有任何用处。此外,虽然我们希望在状态簇之间建立稀疏连接,但为了保持底层图的特性,我们希望保留状态簇之间的桥。
我们将离散时间随机的中餐馆过程算法(discrete-time stochastic Chinese Restaurant Process)作为状态簇的先验。分层结构的发现可以通过倒置生成模型来获得分层 H 的后验概率实现。文献[6]中提出的生成模型可生成上述的分层结构。
3.2 奖励
在图G的背景下,奖励可以解释为顶点(vertices)的可观察特征。由于人们经常基于可观察的特征进行聚类分析,因此对由奖励催生的状态簇建模是合理的[5]。此外,我们假设每个状态交付一个随机确定的奖励,而智能体的目标是将总奖励最大化[8]。
由于我们假设状态簇产生奖励,因此我们将每个状态簇建模为具有平均奖励。状态簇中的每个节点都有从以平均状态簇奖励为中心的分布中提取的平均奖励。最后,每个观察到的奖励都是从以该节点的平均奖励为中心的分布中获得。文献[1]对这一假设进行了正式讨论。
为了简化推论,我们首先假设奖励是恒定的、静止的,又将用某个固定概率在观测值之间变化的奖励标记为动态的奖励。
我们进行了两个实验来检验关于人类行为的假设和研究我们的模型对人类行为的预测能力。更重要的是,我们研究了状态簇在多大程度上推动了对奖励的推断,以及奖励在多大程度上驱动了状态簇的形成。在每个实验中,我们都收集人类数据,并将其与模型的预测结果进行比较。
四、状态簇催生奖励
第一个实验的目标是了解奖励如何在状态簇中泛化。我们进行了一系列测试,希望知道图结构是否驱动了状态簇的形成,以及人们是否将在一个节点上观察到的奖励泛化到了该节点所属的状态簇。
4.1 设置
该实验让32名实验参与者按照接下来所设的场景选择下一个要访问的节点。我们向参与者随机展示下图或下图的简易版,以避免偏手性(handedness)或图结构的偏见。我们预测参与者会选择与位于较大状态簇中的标记节点相邻的节点,比如在第一种情况下,参与者会选择蓝色节点左侧的灰色节点,在第二种情况下会选择蓝色节点右侧的灰色节点。
我们向参与者展示了以下的任务和相关图:
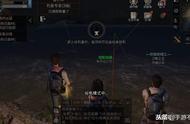
假设你在一个巨大的金矿里工作。金矿由多个独立矿山和隧道组成。金矿的布局如下图所示(每个圆圈代表一个矿井,每条线代表一条隧道)。你的薪酬按日结算,而且当天每发现1克黄金就会获得10美元的报酬。你每天只挖一个矿,并记录下当天的黄金产量(以克为单位)。在过去的几个月里,你发现平均每个矿每天产出约15克黄金。昨天你挖了下图所示的蓝色矿井,获得了30克黄金。那么,对于图中的两个灰色矿井,今天你要选择挖哪一个?请圈出你选择的矿井。

向参与者展示的矿井图
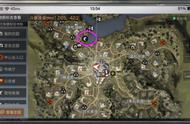
我们希望大多数参与者自动识别以下状态簇(桃黄色和淡紫色的节点分别表示不同的状态簇),并根据脑海里的状态簇决定选择哪个矿井。我们假设,参与者会选择桃黄色的节点而不是淡紫色节点,因为带有标签30、比平均奖励大得多的节点便位于桃红色的状态簇中。

向实验参与者展示的矿井图(显示可能的状态簇)
4.2 推论
我们Metropolis-within-Gibbs算法进行采访,以接近针对 H 的贝叶斯推断。该方法通过从 H 的后验分布中取样更新了 H 的每个成分,在单一Metropolis-Hasting算法步骤中对所有其他成分进行训练。我们使用了高斯随机游走(Gaussian random walk)作为连续成分的建议分布(proposal distribution),并使用条件CRP先验(conditional CRP prior)作为聚类任务的建议分布[7]。该方法可以定义为一种关于由后验定义的关于效用函数(utility function)的随机爬山算法(stochastic hill climbing)。
4.3 结果
人类组和仿真组中各有32名参与者。前三个状态簇的模型输出结果如下图所示(左侧部分)。前三个结果均相同,表明该模型以高置信度(high confidence)识别出彩色分组。参与者的结果以及静态奖励模型的结果可以从下面的条形图中(右图)看到,此图描述了接下来选择访问节点2的人类和模拟参与者的比例。实心黑线表示平均值,黑色虚线则表示第2.5和第97.5个百分位。

状态簇实验中的奖励泛化结果
下表中列出的 p 值经右尾二项检验(right-tailed binomial test)计算获得,其中null值在选择左边或右边的灰色节点时被假设为二项分布。显著性水平取0.05,人类实验结果和模型结果均具有统计学意义。