一、导入相关的依赖包
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.17</version>
</dependency>

三、实现相应的工具类
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.springframework.util.StringUtils;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Wordutil {
public static void main(String[] args) throws Exception {
Wordutil wordutil=new Wordutil();
wordutil.testReadByExtractor("/xxxx/xxxx/xxxxxxxxxx.doc);
}
public void testReadByExtractor(String absolutePath) throws Exception {
InputStream is = new FileInputStream(absolutePath);
WordExtractor extractor = new WordExtractor(is);
//获取各个段落的文本,这种适合简单的文本格式
String paraTexts[] = extractor.getParagraphText();
for (int i=0; i<paraTexts.length; i ) {
System.out.println(paraTexts[i]);
}
this.closeStream(is);
}
/**
* 关闭输入流
* @param is
*/
private void closeStream(InputStream is) {
if (!StringUtils.isEmpty(is)) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

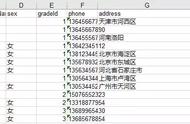
三、如果是表格形式的需要根据是docx版本或者是doc版本使用XWPFDocument,以及HWPFDocument进行读取相应的文件,word文档中表格的读取,如果是用模板.ftl文件导出的word,无法进行相应的读取,需要重新将文件进行另存为,然后再一次读取。
其中需要的依赖包
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.0</version>
</dependency>
<!--处理word文档需要的额外的jar包-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.0</version>
</dependency>
<!--处理word文档需要的额外的jar包-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>4.1.0</version>
</dependency>

四、代码的实现
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.usermodel.*;
import org.apache.poi.poifs.filesystem.POIFSFileSystem;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow;
import org.springframework.util.StringUtils;
import java.io.FileInputStream;
import java.util.Iterator;
import java.util.List;
/**
* word文档中表格的读取,如果是用模板.ftl文件导出的word,无法进行相应的读取,
* 需要将word文档另存为
*/
public class DocTableReadUtil {
/**
* 读取文档中表格
*/
public static String getWord(String filePath) {
String wordContent = "";
String tmpWord = "";//报告录入人: 录入时间:
try {
FileInputStream in = new FileInputStream(filePath);//载入文档
// 处理docx格式 即office2007以后版本
if (filePath.toLowerCase().endsWith("docx")) {
//word 2007 图片不会被读取, 表格中的数据会被放在字符串的最后
XWPFDocument xwpf = new XWPFDocument(in);//得到word文档的信息
Iterator<XWPFTable> it = xwpf.getTablesIterator();//得到word中的表格
// 设置需要读取的表格 set是设置需要读取的第几个表格,total是文件中表格的总数
int set = 4;
// 过滤前面不需要的表格
for (int i = 0; i < set - 1; i ) {
it.hasNext();
it.next();
}
while (it.hasNext()) {
XWPFTable table = it.next();
List<XWPFTableRow> rows = table.getRows();
//读取每一行数据
String tableTxt = "";
for (int i = 0; i < rows.size(); i ) {
XWPFTableRow row = rows.get(i);
String rowTxt = "<tr>";
//读取每一列数据
List<XWPFTableCell> cells = row.getTableCells();
for (int j = 0; j < cells.size(); j ) {
XWPFTableCell cell = cells.get(j);
//输出当前的单元格的数据
//输出结果-------------
}
}
}
} else {
// 处理doc格式 即office2003版本
POIFSFileSystem pfs = new POIFSFileSystem(in);
HWPFDocument hwpf = new HWPFDocument(pfs);
Range range = hwpf.getRange();//得到文档的读取范围
TableIterator it = new TableIterator(range);
// 迭代文档中的表格
// 如果有多个表格只读取需要的一个 set是设置需要读取的第几个表格,total是文件中表格的总数
int set = 4;
for (int i = 0; i < set - 1; i ) {
it.hasNext();
it.next();
}
while (it.hasNext()) {
Table tb = it.next();
//迭代行,默认从0开始,可以依据需要设置i的值,改变起始行数,也可设置读取到那行,只需修改循环的判断条件即可
String table = "";
for (int i = 0; i < tb.numRows(); i ) {
TableRow tr = tb.getRow(i);
//迭代列,默认从0开始
String row = "<tr>";
for (int j = 0; j < tr.numCells(); j ) {
TableCell td = tr.getCell(j);//取得单元格
//取得单元格的内容
for (int k = 0; k < td.numParagraphs(); k ) {
Paragraph para = td.getParagraph(k);
String s = para.text();
//输出结果-------------
}
}
}
}
}
} catch (Exception e) {
//初始化时,处理是否将word转化为html的标签,存入数据库中,如果出现异常抛出
e.printStackTrace();
}
return wordContent;
}
}