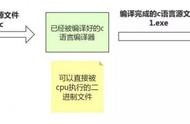
编译器的主要工作流程:源代码 (source code) → 预处理之前的翻译处理→预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 连接器 (Linker) → 可执行程序 (executables)。GCC C语言编译器以汇编代码的形式产生输出, 汇编代码是机器代码的文本表示, 给出程序中的每一条指令。 然后GCC调用汇编器和链接器,根据汇编代码生成可执行的机器代码。
1 预处理之前的翻译处理在预处理之前,编译器必须对该程序进行一些翻译处理。
1.1 编译器把源代码中出现的多字节字符映射到源字符集。
该过程处理多字节字符和三字符序列--字符扩展,让C更加国际化。
如??:表示#(C99可以用%:表示#),??<表示{(C99可以用<%表示>)。
1.2 将物理换行转换成逻辑行
编译器定位每个反斜杠后面跟着换行符的实例, 并删除它们。也就是说, 把下面两个物理行(physical line):
printf("That's wond\
erful!\n");
转换成一个逻辑行(logical line):
printf("That's wonderful!\n");
注意,在这种场合中,“换行符”的意思是通过按下Enter键在源代码文件中换行所生成的字符, 而不是指符号表征\n。
由于预处理表达式的长度必须是一个逻辑行, 所以这一步为预处理器做好了准备工作。一个逻辑行可以是多个物理行。
1.3 特殊文本序列的处理
编译器把文本划分成预处理记号序列、空白序列和注释序列(记号是由空格、制表符或换行符分隔的项)。这里要注意的是, 编译器将用一个空格字符替换每一条注释。因此,下面的代码:
int/*这看起来并不像一个空格*/fox;
将变成:
int fox;
而且,实现可以用一个空格替换所有的空白字符序列(不包括换行符)。
2 预处理预处理器查找一行中以#号开始的预处理指令,做一些文本层面的“查找、替换”工作。预处理包括宏替换(带参与不带参)、文件包含、条件编译、以及其它的一些预处理指令(如pragma)。
3 编译编译器完成源代码到目标代码的转换。对于于强类型语言(如C语言)的编译器,其类型检查在编译阶段完成。
对于函数原型的声明,就是告诉编译器该函数的存在,也就是说,即使没有函数的定义,但有函数原型的声明,编译器也不会报错。当然,到了链接阶段,链接器需要插入函数的定义,此时函数的定义就不能少了。
编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。源代码一般为高级语言 (High-level language), 如Pascal、C、C 、Java、汉语编程等或汇编语言,而目标则是机器语言的目标代码(Object code),有时也称作机器代码(Machine code)。
高级计算机语言便于人编写,阅读交流,维护。机器语言是计算机能直接解读、运行的。
对于C#、VB等高级语言而言,此时编译器完成的功能是把源码(SourceCode)编译成通用中间语言(MSIL/CIL)的字节码(ByteCode)。最后运行的时候通过通用语言运行库的转换,编程最终可以被CPU直接计算的机器码(NativeCode)。
机器代码的生成是优化变型后的中间代码转换成机器指令的过程。现代编译器主要采用生成汇编代码(assembly code)的策略,而不直接生成二进制的目标代码(binary object code)。即使在代码生成阶段,高级编译器仍然要做很多分析,优化,变形的工作。例如如何分配寄存器(register allocatioin),如何选择合适的机器指令(instruction selection),如何合并几句代码成一句等等。
编译器处理的对象是由单个.c或.cpp文件和其中递归包含的头文件组成的编译单元。一般来说,头文件是不直接参与编译的。编译器会将每个编译单元翻译成同名的二进制代码文件,在DOS和Windows环境下,二进制代码文件的后缀名为.obj,在UNIX环境下,其后缀名为.o,此时,二进制代码文件还是零散的,还不是可执行二进制文件。
错误检查大多是在编译阶段进行的,编译器主要进行语法分析、词法分析、产生目标代码,并进行代码优化等处理。为全局变量和静态变量分配内存,并检查函数是否已定义,如没有定义,是否有函数声明,函数声明通知编译器:该函数在本文件后面定义,或者在其他文件中定义。
4 链接链接器将编译得到的零散的二进制代码文件组合成二进制可执行文件。主要完成两个工作,一是解析其他文件中函数引用或其他引用,二是解析库函数。
举例来说,某个程序由两个.c文件组成,分别为A.c、B.c,两个.c文件和其中递归包含的头文件组成两个编译单元,经过预处理和编译生成二进制代码文件A.obj和B.obj。假设A.c中调用了函数C,可函数C定义在B.c中,A.obj中实际上仅仅包括对C函数的引用,其二进制定义代码需要从B.obj中提取,插入A.obj的调用处,这个过程称为函数解析(resolve),由链接器完成。不仅仅是函数,变量(诸如有外部链接性的全局变量)也牵扯到解析的问题。当B.c没有定义函数C时,编译时不会产生错误,但连接时却会提示有未解析的对象,据此可分析出问题出在编译阶段还是链接阶段。
出于商业考虑或保密需要,C标准库函数和其他公司或组织提供的第三方库函数都是以二进制代码形式提供的,后缀名为.lib。在程序中调用了库函数,便需要对库函数进行解析,链接器会从对应的二进制库文件中将函数的代码抽出并插入调用处。如果库中无此函数或找不到对应的库,也会发生未解析(unresolved)的错误。
链接可以在编译时由静态编译器来完成,也可以在加载时和运行时由动态链接器来完成。链接器处理称为目标文件的二进制文件,它有3 种不同的形式:可重定位的、可执行的和共享的。可重定位的目标文件由静态链接器合并成一个可执行的目标文件,它可以加载到内存中并执行。共享目标文件(共享库)是在运行时由动态链接器链接和加载的,或者隐含地在调用程序被加载和开始执行时,或者根据需要在程序调用dlopen 库的函数时。
链接器的两个主要任务是符号解析和重定位,符号解析将目标文件中的每个全局符号都绑定到一个唯一的定义,而重定位确定每个符号的最终内存地址,并修改对那些目标的引用。
加载器将可执行文件的内容映射到内存,并运行这个程序。链接器还可能生成部分链接的可执行目标文件,这样的文件中有对定义在共享库中的例程和数据的未解析的引用。在加载时,加载器将部分链接的可执行文件映射到内存,然后调用动态链接器,它通过加载共享库和重定位程序中的引用来完成链接任务。
被编译为位置无关代码的共享库可以加载到任何地方,也可以在运行时被多个进程共享。为了加载、链接和访问共享库的函数和数据,应用程序也可以在运行时使用动态链接器。
在早期的计算机系统中,链接是手动执行的。在现代系统中,链接是由叫做链接器(linker)的程序自动执行的。链接器在软件开发中扮演着一个关键的角色,因为它们使得分离编译(separate compilation)成为可能。我们不用将一个大型的应用程序组织为一个巨大的源文件,而是可以把它分解为更小、更好管理的模块,可以独立地修改和编译这些模块。当我们改变这些模块中的一个时,只需简单地重新编译它,并重新链接应用,而不必重新编译其他文件。
链接器可以读取一组可重定位目标文件,并把它们链接起来,形成一个输出的可执行文件。实际上,所有的编译系统都提供一种机制,将所有相关的函数可以被编译为独立的目标模块,然后封装成一个单独的静态库文件,称为静态库(static library), 它可以用做链接器的输入。
在链接时,链接器将只复制被程序引用的目标模块,这就减少了可执行文件在磁盘和内存中的大小。在Linux 系统中,静态库以一种称为存档(archive)的特殊文件格式存放在磁盘中。存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。存档文件名由后缀.a 标识。Linux 系统为动态链接器提供了一个简单的接口,允许应用程序在运行时加载和链接创建一个共享库。

-End-
,