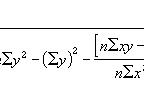现在好多留学日本机构都会告诉你偏差值计算可以按照下面两个图来算,但是具体怎么实现的,没有一家说得清楚,所以下面我通过一组样本计算来解释下什么是偏差值!


例如,我们有 4 名学生参加宝仙(我们合作的日本高中 )入学考试,其中3人合格,如下表,其标准差可通过以下步骤计算:
数学 | 小圆(合格) | 小佳(合格) | 小红(合格) | 小绿(不合格) |
分数 | 90 | 80 | 70 | 60 |
计算标准差的步骤通常有四步:
计算平均值、计算各个数据与平均值的差的平方、计算方差、计算标准差。
- 计算平均值:
- 计算各个数据与平均值的差的平方:
小绿:
小红:
小佳:
小圆:
- 计算方差:
- 计算标准差:
我们算出了标准差!!!这次四人考试,标准差是 11.1803
二、现在我们来算下个人偏差值:
为啥要加 50?因为 100 分试卷中间值是 50,如果大家炒股,那么平均值 标准差就是天花板,平均值-标准差就是地板!!!一个小知识点
我们来带入3名合格学员的成绩,计算下他们偏差吧:
唉?小圆为啥只有 63.42 啊???小圆不是第一吗,但是偏差却不像我们常见的高值 70 吗???再看看小红,偏差只有 45.53,但是宝仙这所高中偏差不是 64 吗?他们三是怎么合格的那?我们公式算错了吗?

答案不是,原因很简单:因为我们样本数太少了。。。。。
样本数越大,标准差会越小,就好比上图 ,集中在中间档位的人很多,会拉低标准差,那么个人成绩越好,相对个人偏差值也会越大。(因为标准差在分母上,分母越小值越大,这个就不用解释了吧)
宝仙这份试卷同样还考了国内日本学生,那么把我们这 3 名学生放入日本考生的大池子中,他们的偏差自然就会上升到宝仙要求的 64 以上,这点大家理解了吧!

经过上面这些计算,大家看下我们滋庆出去的某位学生,在全日本统考的偏差值,87.2的偏差值可想而知有多难!!!!
三、日本大学偏差怎么来的?我们先看下日本大学学部偏差的定义:
例:“东京大学工学部偏差值定为 70,总考生人数为 10000 人,偏差值的成绩排名为 228”在这个条件设定下,意味着当你参加这个专业的考试,最终成绩排名在前 228 名以内,则达到了偏差值 70 的要求,就有极大的机会考上该专业。那么高中的偏差定义和大学是一样的,偏差越高,说明招收学生的排名就在全国考生的头部,这点好理解吧! 下图为日本高中偏差值和国内高中的比较!
70以上 | S类(相当于国内当地最好的高中) |
65-69 | A类高中 (相当于国内的一般市重点) |
60-64 | B类高中 (相当于国内的区重点) |
因为偏差值不同于排名,加入了考生之间考分差这个因素,所以可以规避每次考试的难易程度,乃至想和上届考试情况进行比较,都能够真实反映出个人的竞争力,是不是有了确切的提升,那么可能有人会问,直接看排名不是更为准确吗?
那么我觉得偏差值可以确切知道你和其他人的差距是多少,说回我们的例子吧!小圆考了第一,小佳考了第二,从排名我们只知道差了一名,但是实际他们考分差了 10 分,在考生基数非常大的情况下,你想知道自己和别人确切的差距吗?那么数据是不会骗人的(《阿基米德大战》中的名言啊)
数学 | 小圆(合格) | 小佳(合格) | 小红(合格) | 小绿(不合格) |
分数 | 90 | 80 | 70 | 60 |
,标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义为方差的算术平方根,反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种性质:一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。其公式如下所列。标准差的观念是由卡尔·皮尔逊(Karl Pearson)引入到统计中。