注:除了拳击和踢腿外,图片目录中最多的是“其他”部分,主要是走动、转身、开关视频录制的一些画面。如果这部分内容太多,会有风险导致训练后的模型产生偏见,把应该归于前两类的图片划分到“其他”中,因此我们减少了这部分图片的量。
如果只使用这600张相同环境、相同人物的图片,我们将无法获得很高的准确度。为了进一步提高识别的准确度,我们将使用数据增强对样本进行扩充。
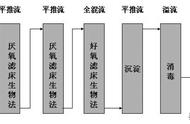
数据增强数据增强是一种通过已有数据集合成新样本的技术,可以帮助我们增加数据集的样本量和多样性。我们可以将原始图片处理一下转变成新图,但处理过程不能太过激烈,好让机器能够对新图片正确归类。
常见的处理图片的方式有旋转、反转颜色、模糊等等。网上已有现成软件,我将使用一款由Python编写的imgaug的工具(项目地址见附录),我的数据增强代码如下:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path "/" filename ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5), # horizontally flip 50% of all images # crop images by -5% to 10% of their height/width sometimes(iaa.CropAndPad( percent=(-0.05, 0.1), pad_mode=ia.ALL, pad_cval=(0, 255) )), sometimes(iaa.Affine( scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # scale images to 80-120% of their size, individually per axis translate_percent={"x": (-0.1, 0.1), "y": (-0.1, 0.1)}, # translate by -10 to 10 percent (per axis) rotate=(-5, 5), shear=(-5, 5), # shear by -5 to 5 degrees order=[0, 1], # use nearest neighbour or bilinear interpolation (fast) cval=(0, 255), # if mode is constant, use a cval between 0 and 255 mode=ia.ALL # use any of scikit-image's warping modes (see 2nd image from the top for examples) )), iaa.Grayscale(alpha=(0.0, 1.0)), iaa.Invert(0.05, per_channel=False), # invert color channels # execute 0 to 5 of the following (less important) augmenters per image # don't execute all of them, as that would often be way too strong iaa.SomeOf((0, 5), [ iaa.OneOf([ iaa.GaussianBlur((0, 2.0)), # blur images with a sigma between 0 and 2.0 iaa.AverageBlur(k=(2, 5)), # blur image using local means with kernel sizes between 2 and 5 iaa.MedianBlur(k=(3, 5)), # blur image using local medians with kernel sizes between 3 and 5 ]), iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)), # emboss images iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.01*255), per_channel=0.5), # add gaussian noise to images iaa.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value) iaa.AddToHueAndSaturation((-20, 20)), # change hue and saturation # either change the brightness of the whole image (sometimes # per channel) or change the brightness of subareas iaa.OneOf([ iaa.Multiply((0.9, 1.1), per_channel=0.5), iaa.FrequencyNoiseAlpha( exponent=(-2, 0), first=iaa.Multiply((0.9, 1.1), per_channel=True), second=iaa.ContrastNormalization((0.9, 1.1)) ) ]), iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5), # improve or worsen the contrast ], random_order=True ) ], random_order=True ) im = np.zeros((16, 56, 100, 3), dtype=np.uint8) for c in range(0, 16): im[c] = image for im in range(len(grid)): misc.imsave(aug_path "/" filename "_" str(im) ".jpg", grid[im])
每张图片最后都被扩展成16张照片,考虑到后面训练和评估时的运算量,我们减小了图片体积,每张图的分辨率都被压缩成100*56。

现在,我们开始建立图片分类模型。处理图片使用的是CNN(卷积神经网络),CNN适合于图像识别、物体检测和分类领域。
迁移学习
迁移学习允许我们使用已被训练过网络。我们可以从任何一层获得输出,并把它作为新的神经网络的输入。这样,训练新创建的神经网络能达到更高的认知水平,并且能将源模型从未见过的图片进行正确地分类。
我们在文中将使用MobileNet神经网络(安装包地址见附录),它和VGG-16一样强大,但是体积更小,在浏览器中的载入时间更短。
在浏览器中运行模型在这一部分,我们将训练一个二元分类模型。
首先,我们浏览器的游戏脚本MK.js中运行训练过的模型。代码如下:
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
以上代码中一些变量和函数的注释:
- video:页面中的HTML5视频元素
- Layer:MobileNet层的名称,我们从中获得输出并把它作为我们模型的输入
- mobilenetInfer:从MobileNet接受例子,并返回另一个函数。返回的函数接受输入,并从MobileNet特定层返回相关的输出
- canvas:将取出的帧指向HTML5的画布
- scale:压缩帧的画布
第二步,我们从摄像头获取视频流,作为视频元素的源。对获得的图像进行灰阶滤波,改变其内容:
const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i = 4) { const avg = (data[i] data[i 1] data[i 2]) / 3; data[i] = avg; data[i 1] = avg; data[i 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
第三步,把训练过的模型和游戏脚本MK.js连接起来。
let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
在以上代码中,我们将MobileNet的输出传递给mobilenetInfer方法,从而获得了从网络的隐藏层中获得输出的快捷方式。此外,我还引用了startInterval。
const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
startInterval正是关键所在,它每间隔100ms引用一个匿名函数。在这个匿名函数中,我们把视频当前帧放入画布中,然后压缩成100*56的图片后,再用于灰阶滤波器。
在下一步中,我们把压缩后的帧传递给MobileNet,之后我们将输出传递给训练过的模型,通过dataSync方法返回一个一维张量punching。
最后,我们通过punching来确定拳击的概率是否高于0.4,如果是,将调用onPunch方法,现在我们可以控制一种动作了:

在这部分,我们将介绍一个更智能的模型:使用神经网络分辨三种动作:拳击、踢腿和站立。
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length kicks.length others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
我们对压缩和灰阶化的图片调用MobileNet,之后将输出传递给训练过的模型。 该模型返回一维张量,我们用dataSync将其转换为一个数组。 下一步,通过使用Array.from我们将类型化数组转换为JavaScript数组,数组中包含我们提取帧中三种姿势的概率。
如果既不是踢腿也不是拳击的姿势的概率高于0.4,我们将返回站立不动。 否则,如果显示高于0.32的概率拳击,我们会向MK.js发出拳击指令。 如果踢腿的概率超过0.32,那么我们发出一个踢腿动作。
以下就是完整的演示效果:

如果我们收集到更大的多样性数据集,那么我们搭建的模型就能更精确处理每一帧。但这样就够了吗?显然不是,请看以下两张图: