每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此hdfs存储小文件会非常低效。因为大量的小文件会耗尽namenode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。每个块的大小可以通过配置参数(dfs.blocksize)来规定,默认的大小128M。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。

hadoop 高可用环境部署,可参考我之前的文章:
- 动态分区插入数据,产生大量的小文件,从而导致 map 数量剧增;
- reduce 数量越多,小文件也越多,reduce 的个数和输出文件个数一致;
- 数据源本身就是大量的小文件;
同样对于如何设置每个文件块的大小,官方给出了这样的建议:

3)HDFS分块目的所以对于块大小的设置既不能太大,也不能太小,太大会使得传输时间加长,程序在处理这块数据时会变得非常慢,如果文件块的大小太小的话会增加每一个块的寻址时间。所以文件块的大小设置取决于磁盘的传输速率。
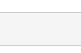
二、HDFS小文件问题处理方案HDFS中分块可以减少后续中MapReduce程序执行时等待文件的读取时间,HDFS支持大文件存储,如果文件过大10G不分块在读取时处理数据时就会大量的将时间耗费在读取文件中,分块可以配合MapReduce程序的切片操作,减少程序的等待时间。

HDFS中文件上传会经常有小文件的问题,每个块大小会有150字节的大小的元数据存储namenode中,如果过多的小文件每个小文件都没有到达设定的块大小,都会有对应的150字节的元数据,这对namenode资源浪费很严重,同时对数据处理也会增加读取时间。对于小文件问题,Hadoop本身也提供了几个解决方案,分别为:Hadoop ArcHive,Sequence File和CombineFileInputFormat,除了hadoop本身提供的方案,当然还有其它的方案,下面会详细讲解。
Hadoop Archive(HAR) 是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。