阅读此文前,麻烦您点击一下“关注”,既方便您进行讨论与分享,又给您带来不一样的参与感,感谢您的支持。

求关注
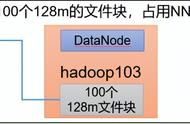
一、HDFS读流程图
HDFS读流程图
二、HDFS详细读流程Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)是大规模数据存储和处理的关键组件之一。在HDFS中,数据被分割成多个块,并分布在多个集群节点上,以实现高可靠性和高性能的数据访问。在本文中,我们将详细介绍HDFS的读流程步骤。

HDFS的读流程可以概括为客户端向NameNode发送读取请求,NameNode返回相应的数据块信息,并通过DataNode将数据块传输给客户端。下面是HDFS的读流程的详细步骤:
1. 客户端发送读取请求:客户端通过HDFS API向NameNode发送读取请求,请求指定要读取的文件的路径和偏移量。
2. NameNode响应:NameNode收到读取请求后,会检查所请求的文件是否存在以及客户端是否有足够的权限进行读取。如果检查通过,NameNode将返回包含文件的块信息的数据块映射列表给客户端。
3. 数据块位置:客户端收到数据块映射列表后,根据列表中的数据块位置信息,确定要读取的数据块存储在哪些DataNode上。
4. 客户端与DataNode建立连接:客户端根据数据块位置信息与存储有数据块的DataNode建立连接。如果某个DataNode不可用,客户端会选择下一个可用的DataNode。
5. 数据传输:客户端通过与DataNode建立的连接,向DataNode发送读取数据块的请求。DataNode接收到请求后,会从磁盘上读取相应的数据块,并通过网络将数据块传输给客户端。
6. 数据传输确认:客户端接收到数据块后,会向DataNode发送确认消息,表示已成功接收到数据。
7. 块副本:如果数据块有多个副本,客户端可能会从多个DataNode上获取数据块的副本。这种情况下,客户端会选择最近的DataNode进行数据读取,以提高读取性能。
8. 读取完成:当客户端收到所需数据块的所有副本后,读取过程完成。客户端可能会在本地缓存中保存数据块,以便后续的读取操作。

总结起来,HDFS的读流程包括客户端发送读取请求,NameNode返回数据块信息,客户端与DataNode建立连接并进行数据传输,直到读取完成。这种分布式的读取方式能够提供高性能和可靠性,适用于大规模数据存储和处理的场景。
最后,由于平台规则,只有当您跟我有更多互动的时候,才会被认定为铁粉。如果您喜欢我的文章,可以点个“关注”,成为铁粉后能第一时间收到文章推送。

点赞
,