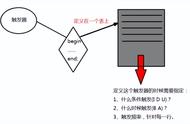
我们从上图发现,横轴越大其bad率越高,而混淆矩阵就是基于上述的预测结果生成的。
我们取任何一个x值进行分段,如x=0.5,x<0.5我们认为是好人,x>0.5我们认为是坏人,但是这样的认定会有误差,即有可能把实际的好人误判为坏人,也有可能把实际的坏人漏过判为好人,这就形成了在这个分界点下的混淆矩阵(即绿的是对的):
每一个x值(即分界点)都会形成一个混淆矩阵,而每一个混淆矩阵都会有很多判别指标:如accuracy、TPR、FPR,就是基于TP\FP\FN\TN四个值的加/除,请读者自行百度,我也不记得了。
2.2 ks值
KS(Kolmogorov-Smirnov)用于模型风险区分能力进行评估,指标衡量的是好坏样本累计分部之间的差值。好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。
KS值的计算也是基于上述的混淆矩阵。KS的计算步骤如下:
- 计算每个评分区间的好坏账户数;
- 计算每个评分区间的累计好账户数占总好账户数比率(good%)和累计坏账户数占总坏账户数比率(bad%);
- 计算每个评分区间累计坏账户占比与累计好账户占比差的绝对值(累计good%-累计bad%);
- 然后对这些绝对值取最大值即得此模型的K-S值。
说人话就是在某个分割点对应的混淆矩阵中,坏人被识别出来的比例(70%的坏人可以被识别出来)-误*好样本的比例(如30%的好人被错当成坏人了)。
因为分割点可以有无数个,我们可以得到一个曲线,max(坏人被识别出来的比例-误*好样本的比例)的点即为最佳KS值。
在建模中模型的ks要求是达到0.3以上才是可以接受的。
除了上述两个评价指标之外,还有基尼系数、PSI、AUC等多个评价指标,主要评价的目的是判定模型的区分度、稳定性等,读者有兴趣可以自行搜索学习。
结语篇
当前大数据背景下的互联网业务形态,给风控这个已经很古老的名词又赋予了新的意义、新的内涵、新的使命,互联网业务形态的复杂性、数据爆炸特性,导致风控的玩法也愈加多样。本文主要是一个科普帖,把当前互联网风控业务内部各环节遇到的一些特定名词给大家尝试做一些浅尝辄止的介绍。
业务、系统、模型各职能模块间是相辅相成的,无论做哪方面的工作,理解更多的工作内容才能打破职能模块间的壁垒、更好的去推进工作!
作者:独孤qiu败,*互联网风控那些事儿(anti_fraud_share),互联网行业风控产品经理,定期分享互联网风控相关业界动态、系统设计方案、模型算法
本文由 @独孤qiu败 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pexels,基于 CC0 协议
,