在上一篇文章中,我们了解了爬虫的原理以及要实现爬虫的三个主要步骤:下载网页-分析网页-保存数据。
下面,我们就来看一下:如何使用Python下载网页。
1、网页是什么?浏览器画网页的流程,是浏览器将用户输入的网址告诉网站的服务器,然后网站的服务器将网址对应的网页返回给浏览器,由浏览器将网页画出来。
这里所说的网页,一般都是一个后缀名为 html 的文件。
网页文件和我们平时打交道的文件没什么不同,平时我们知道 Word 文件,后缀名为 .doc, 通过 Word 可以打开。图片文件后缀名为 .jpg,通过 Photoshop 可以打开;而网页则是后缀名为 .HTML,通过浏览器可以打开的文件。
网页文件本质也是一种文本文件,为了能够让文字和图片呈现各种各样不同的样式,网页文件通过一种叫作 HTML 语法的标记规则对原始文本进行了标记。
(1)手动下载网页我们以煎蛋网为例体会一下网页的实质,使用浏览器打开这个链接http://jandan.net/可以看到如下界面。可以看到,第一条新闻的标题前缀是:今日好价。网页内容可能会随时间变化,这里你只需要注意第一条新闻的前几个字(暗号)即可,下同。

在空白区域点击右键,另存为,并在保存类型中选择:仅 HTML。
接下来回到桌面,可以看到网页已经被保存到桌面了,后缀名是 html,这个就是我们所说的网页文件。
(2)网页内容初探我们右键刚下载的文件,选择用 VS Code 打开,打开后的文件内容如下图所示。

这就是网页文件的实际内容(未被浏览器画出来之前)。现在先不用管看不懂的代码,还记得我们看到的第一条新闻吗?“今日好价………………”。(你的暗号)
我们在 VS Code 中通过 CTRL F 调出搜索面板,搜索“今日好价”(暗号)。可以看到成功找到了这条新闻,虽然被很多不认识的代码包围,但这也可以确定,我们看到的煎蛋网的主页确实就是这个 html 文件。

Python 以系统类的形式提供了下载网页的功能,放在 urllib3 这个模块中。这里面有比较多的类,我们并不需要逐一都用一遍,只需要记住主要的用法即可。
(1)获取网页内容还是以煎蛋网为例。在我们打开这个网页的时候,排在第一的新闻是:“天文学家首次见证黑洞诞生”。
煎蛋又更新了新的新闻,你记住你当时的第一条新闻题目即可。我们待会儿会在我们下载的网页中搜索这个标题来验证我们下载的正确性。
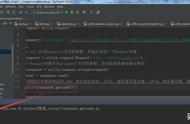
下面开始,打开vscode,输入如下代码:
# 导入 urllib3 模块的所有类与对象
import urllib3
# 将要下载的网址保存在 url 变量中,英文一般用 url 表示网址的意思
url = "http://jandan.net/p/date/2021/03/23"
# 创建一个 PoolManager 对象,命名为 http
http = urllib3.PoolManager()
# 调用 http 对象的 request 方法,第一个参数传一个字符串 "GET"
# 第二个参数则是要下载的网址,也就是我们的 url 变量
# request 方法会返回一个 HTTPResponse 类的对象,我们命名为 response
response = http.request("GET", url)
# 获取 response 对象的 data 属性,存储在变量 response_data 中
response_data = response.data
# 调用 response_data 对象的 decode 方法,获得网页的内容,存储在 html_content
# 变量中
html_content = response_data.decode()
# 打印 html_content
print(html_content)
上述代码就完成了一个完成的网页下载的功能。其中有几个额外要注意的点:
- 我们创建 PoolManager的时候,写的是 urllib3.PoolManager,这里是因为我们导入了 urllib3 的所有类与函数。所以在调用这个模块的所有函数和类的前面都需要加模块名,并用点符号连接。
- response 对象的 data 属性也是一个对象,是一个 bytes 类型的对象。通过调用 decode 方法,可以转化成我们熟悉的字符串。
执行上述代码,可以看到打印出了非常多的内容,而且很像我们第一部分手动保存的网页,这说明目前 html_content 变量中保存的就是我们要下载的网页内容。