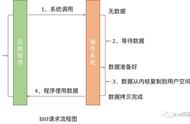
epoll_wait 工作流程概述
对照代码:linux-2.6.11.12/fs/eventpoll.c:
1)epoll_wait 调用 ep_poll
- 当 rdlist(ready-list) 为空(无就绪fd)时挂起当前线程,直到 rdlist 不为空时线程才被唤醒。
2)文件描述符 fd 的 events 状态改变
- buffer由不可读变为可读或由不可写变为可写,导致相应fd上的回调函数ep_poll_callback被触发。
3)ep_poll_callback 被触发
- 将相应fd对应epitem加入rdlist,导致rdlist不空,线程被唤醒,epoll_wait得以继续执行。
4)执行 ep_events_transfer 函数
- 将rdlist中的epitem拷贝到txlist中,并将rdlist清空。
- 如果是epoll LT,并且fd.events状态没有改变(比如buffer中数据没读完并不会改变状态),会再重新将epitem放回rdlist。
5)执行 ep_send_events 函数
- 扫描txlist中的每个epitem,调用其关联fd对应的poll方法取得较新的events。
- 将取得的events和相应的fd发送到用户空间。
8 Netty 的最佳实践
1)业务线程池必要性
- 业务逻辑尤其是阻塞时间较长的逻辑,不要占用netty的IO线程,dispatch到业务线程池中去。
2)WriteBufferWaterMark
- 注意默认的高低水位线设置(32K~64K),根据场景适当调整(可以思考一下如何利用它)。
3)重写 MessageSizeEstimator 来反应真实的高低水位线
- 默认实现不能计算对象size,由于write时还没路过任何一个outboundHandler就已经开始计算message size,此时对象还没有被encode成Bytebuf,所以size计算肯定是不准确的(偏低)。
4)注意EventLoop#ioRatio的设置(默认50)
- 这是EventLoop执行IO任务和非IO任务的一个时间比例上的控制。
5)空闲链路检测用谁调度?
- Netty4.x默认使用IO线程调度,使用eventLoop的delayQueue,一个二叉堆实现的优先级队列,复杂度为O(log N),每个worker处理自己的链路监测,有助于减少上下文切换,但是网络IO操作与idle会相互影响。
- 如果总的连接数小,比如几万以内,上面的实现并没什么问题,连接数大建议用HashedWheelTimer实现一个IdleStateHandler,HashedWheelTimer复杂度为 O(1),同时可以让网络IO操作和idle互不影响,但有上下文切换开销。
6)使用ctx.writeAndFlush还是channel.writeAndFlush?
- ctx.write直接走到下一个outbound handler,注意别让它违背你的初衷绕过了空闲链路检测。
- channel.write从末尾开始倒着向前挨个路过pipeline中的所有outbound handlers。
7)使用Bytebuf.forEachByte() 来代替循环 ByteBuf.readByte()的遍历操作,避免rangeCheck()
8)使用CompositeByteBuf来避免不必要的内存拷贝
- 缺点是索引计算时间复杂度高,请根据自己场景衡量。
9)如果要读一个int,用Bytebuf.readInt(),不要Bytebuf.readBytes(buf,0,4)
- 这能避免一次memory copy (long,short等同理)。
10)配置UnpooledUnsafeNoCleanerDirectByteBuf来代替jdk的DirectByteBuf,让netty框架基于引用计数来释放堆外内存
io.netty.maxDirectMemory:
- < 0: 不使用cleaner,netty方面直接继承jdk设置的最大direct memory size,(jdk的direct memory size是独立的,这将导致总的direct memory size将是jdk配置的2倍)。
- == 0: 使用cleaner,netty方面不设置最大direct memory size。
0:不使用cleaner,并且这个参数将直接限制netty的最大direct memory size,(jdk的direct memory size是独立的,不受此参数限制)。
11)最佳连接数
- 一条连接有瓶颈,无法有效利用cpu,连接太多也白扯,最佳实践是根据自己场景测试。
12)使用PooledBytebuf时要善于利用 -Dio.netty.leakDetection.level 参数
- 四种级别:DISABLED(禁用),SIMPLE(简单),ADVANCED(高级),PARANOID(偏执)。
- SIMPLE,ADVANCED采样率相同,不到1%(按位与操作 mask ==128 - 1)。
- 默认是SIMPLE级别,开销不大。
- 出现泄漏时日志会出现“LEAK: ”字样,请时不时grep下日志,一旦出现“LEAK: ”立刻改为ADVANCED级别再跑,可以报告泄漏对象在哪被访问的。
- PARANOID:测试的时候建议使用这个级别,100%采样。
13)Channel.attr(),将自己的对象attach到channel上
- 拉链法实现的线程安全的hash表,也是分段锁(只锁链表头),只有hash冲突的情况下才有锁竞争(类似ConcurrentHashMapV8版本)。
- 默认hash表只有4个桶,使用不要太任性。
9 从 Netty 源码中学到的代码技巧
1)海量对象场景中 AtomicIntegerFieldUpdater --> AtomicInteger
- Java中对象头12 bytes(开启压缩指针的情况下),又因为Java对象按照8字节对齐,所以对象最小16 bytes,AtomicInteger大小为16 bytes,AtomicLong大小为 24 bytes。
- AtomicIntegerFieldUpdater作为static field去操作volatile int。
2)FastThreadLocal,相比jdk的实现更快
- 线性探测的Hash表 —> index原子自增的裸数组存储。
3)IntObjectHashMap / LongObjectHashMap …
- Integer—> int
- Node[] —> 裸数组
4)RecyclableArrayList
- 基于前面说的Recycler,频繁new ArrayList的场景可考虑。
5)JCTools
- 一些jdk没有的 SPSC/MPSC/SPMC/MPMC 无锁并发队以及NonblockingHashMap(可以对比ConcurrentHashMapV6/V8)
作者 | 家纯
本文为阿里云原创内容,未经允许不得转载。