从bytes in flight也大致能算出来总的传输时间 16K*1000/20=800Kb/秒
我们的应用会默认设置 socketSendBuffer 为16K:
socket.setSendBufferSize(16*1024) //16K send buffer
来看一下tcp包发送流程:

图片来源:陶辉

如果sendbuffer不够就会卡在上图中的第一步 sk_stream_wait_memory,通过systemtap脚本可以验证:
#!/usr/bin/stap # Simple probe to detect when a process is waiting for more socket send # buffer memory. Usually means the process is doing writes larger than the # socket send buffer size or there is a slow receiver at the other side. # Increasing the socket's send buffer size might help decrease application # latencies, but it might also make it worse, so buyer beware. # Typical output: timestamp in microseconds: procname(pid) event # # 1218230114875167: python(17631) blocked on full send buffer # 1218230114876196: python(17631) recovered from full send buffer # 1218230114876271: python(17631) blocked on full send buffer # 1218230114876479: python(17631) recovered from full send buffer probe kernel.function("sk_stream_wait_memory") { printf("%u: %s(%d) blocked on full send buffern", gettimeofday_us(), execname(), pid()) } probe kernel.function("sk_stream_wait_memory").return { printf("%u: %s(%d) recovered from full send buffern", gettimeofday_us(), execname(), pid()) }
原理解析
如果tcp发送buffer也就是SO_SNDBUF只有16K的话,这些包很快都发出去了,但是这16K不能立即释放出来填新的内容进去,因为tcp要保证可靠,万一中间丢包了呢。只有等到这16K中的某些包ack了,才会填充一些新包进来然后继续发出去。由于这里rt基本是20ms,也就是16K发送完毕后,等了20ms才收到一些ack,这20ms应用、内核什么都不能做,所以就是如第二个图中的大概20ms的等待平台。
sendbuffer相当于发送仓库的大小,仓库的货物都发走后,不能立即腾出来发新的货物,而是要等对方确认收到了(ack)才能腾出来发新的货物。 传输速度取决于发送仓库(sendbuffer)、接收仓库(recvbuffer)、路宽(带宽)的大小,如果发送仓库(sendbuffer)足够大了之后接下来的瓶颈就是高速公路了(带宽、拥塞窗口)。
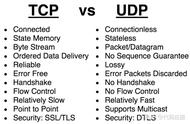
如果是UDP,就没有可靠的概念,有数据统统发出去,根本不关心对方是否收到,也就不需要ack和这个发送buffer了。
几个发送buffer相关的内核参数
vm.lowmem_reserve_ratio = 256 256 32 net.core.wmem_max = 1048576 net.core.wmem_default = 124928 net.ipv4.tcp_wmem = 4096 16384 4194304 net.ipv4.udp_wmem_min = 4096
net.ipv4.tcp_wmem 默认就是16K,而且是能够动态调整的,只不过我们代码中这块的参数是很多年前从Cobra中继承过来的,初始指定了sendbuffer的大小。代码中设置了这个参数后就关闭了内核的动态调整功能,但是能看到http或者scp都很快,因为他们的send buffer是动态调整的,所以很快。
接收buffer是有开关可以动态控制的,发送buffer没有开关默认就是开启,关闭只能在代码层面来控制:
net.ipv4.tcp_moderate_rcvbuf
优化
调整 socketSendBuffer 到256K,查询时间从25秒下降到了4秒多,但是比理论带宽所需要的时间略高。
继续查看系统 net.core.wmem_max 参数默认最大是130K,所以即使我们代码中设置256K实际使用的也是130K,调大这个系统参数后整个网络传输时间大概2秒(跟100M带宽匹配了,scp传输22M数据也要2秒),整体查询时间2.8秒。测试用的mysql client短连接,如果代码中的是长连接的话会块300-400ms(消掉了慢启动阶段),这基本上是理论上最快速度了。

如果指定了tcp_wmem,则net.core.wmem_default被tcp_wmem的覆盖。send Buffer在tcp_wmem的最小值和最大值之间自动调整。如果调用setsockopt()设置了socket选项SO_SNDBUF,将关闭发送端缓冲的自动调节机制,tcp_wmem将被忽略,SO_SNDBUF的最大值由net.core.wmem_max限制。
BDP 带宽时延积
BDP=rtt*(带宽/8)
这个 buffer 调到1M测试没有帮助,从理论计算BDP(带宽时延积) 0.02秒*(100MB/8)=250Kb 所以SO_SNDBUF为256Kb的时候基本能跑满带宽了,再大实际意义也不大了。也就是前面所说的仓库足够后瓶颈在带宽上了。
因为BDP是250K,也就是拥塞窗口(带宽、接收窗口和rt决定的)即将成为新的瓶颈,所以调大buffer没意义了。
用tc构造延时和带宽限制的模拟重现环境
sudo tc qdisc del dev eth0 root netem delay 20ms sudo tc qdisc add dev eth0 root tbf rate 500kbit latency 50ms burst 15kb
这个案例关于wmem的结论
默认情况下Linux系统会自动调整这个buffer(net.ipv4.tcp_wmem), 也就是不推荐程序中主动去设置SO_SNDBUF,除非明确知道设置的值是最优的。
从这里我们可以看到,有些理论知识点虽然我们知道,但是在实践中很难联系起来,也就是常说的无法学以致用,最开始看到抓包结果的时候比较怀疑发送、接收窗口之类的,没有直接想到send buffer上,理论跟实践的鸿沟。
说完发送Buffer(wmem)接下来我们接着一看看接收buffer(rmem)和接收窗口的情况
用这样一个案例下来验证接收窗口的作用:
有一个batch insert语句,整个一次要插入5532条记录,所有记录大小总共是376K。
SO_RCVBUF很小的时候并且rtt很大对性能的影响
如果rtt是40ms,总共需要5-6秒钟:
基本可以看到Server一旦空出来点窗口,client马上就发送数据,由于这点窗口太小,rtt是40ms,也就是一个rtt才能传3456字节的数据,整个带宽才80-90K,完全没跑满。