Apache Spark 和 Apache Hive 都是大数据处理领域的重要工具。然而,它们之间存在着明显的差异,并且是为满足不同的用例而设计的。本文将深入探讨这两个工具的核心功能、特点以及它们在实际应用中的优劣势。
1. 简介
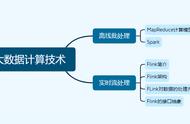
Apache Spark: 是一个快速、通用、扩展性强的大数据计算框架,支持批处理、实时流处理、机器学习、图计算等多种大数据处理模式。
Apache Hive: 是建立在Hadoop之上的数据仓库工具,它提供了一种类SQL的查询语言(HiveQL),允许开发者方便地查询、汇总和分析存储在Hadoop中的大数据。
2. 数据处理
Spark: 使用Resilient Distributed Dataset (RDD) 和 DataFrame 作为主要的数据结构,能够进行快速的分布式数据处理。
Hive: 主要使用HiveQL进行数据查询。虽然HiveQL是一个高级查询语言,但它最终会被转化为MapReduce任务来进行数据处理。
3. 性能
Spark: 设计初衷就是为了解决MapReduce的性能问题。它支持内存中的计算,大大减少了读写磁盘的需要,从而大大加快了计算速度。
Hive: 传统上依赖于MapReduce进行数据处理,这通常比Spark慢得多,尤其是在处理大规模数据时。然而,随着Hive的发展,现在它也支持像Tez和Spark这样的执行引擎,从而提高了性能。
4. 用例
Spark: 由于其广泛的功能和库(如Spark Streaming, Spark MLlib等),它适合实时数据处理、机器学习、图形处理等多种用例。
Hive: 更多地用于批处理和OLAP场景,尤其是当数据仓库查询和简单的数据分析需求时。
5. 语言支持
Spark: 支持Scala、Java、Python和R等多种语言。
Hive: 主要使用HiveQL,但也可以使用用户定义的函数(UDFs)进行扩展,这些UDFs可以用Java编写。
6. 社区和生态系统
Spark: 有一个非常活跃的开发和用户社区,以及一系列的附加库和工具,如Spark Streaming, Spark MLlib等。
Hive: 作为Hadoop生态系统的一部分,Hive也有一个强大和活跃的社区。随着时间的推移,Hive已经获得了许多性能和功能上的改进。
7. 结论
选择Spark或Hive取决于特定的用例和需求:
对于需要实时处理、机器学习或图处理的应用程序,Spark可能是更好的选择。
对于主要基于SQL的数据分析和OLAP查询,尤其是在Hadoop生态系统中,Hive可能更有优势。
但值得注意的是,Spark和Hive并不是互斥的。实际上,许多组织在其大数据处理管道中同时使用这两个工具,从而结合了两者的优势。
,