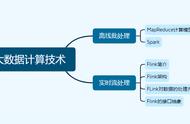
大数据要实现业务落地的前提,是企业需要搭建起自身的大数据平台,去实现对数据价值的挖掘和应用。根据实际的业务场景需求,不同类型的数据,需要不同的计算处理模式。今天我们就来聊聊批处理和流处理两种大数据计算模式。
数据驱动策略的到来,使得企业对自身所拥有的数据资源开始有了更深刻的认识,意识到数据的价值之后,接下来就是要实现对这些数据的价值挖掘。

企业搭建大数据平台,目前行业当中的主流选择,集中在Hadoop(MapReduce)、Spark、Storm、Flink等几个框架上,这其中包括批处理、流处理、以及两者兼具的选择。对于企业而言,就需要根据自身的需求及成本、人力等方面的考虑,来进行技术选型。
批处理模式:典型的批处理框架就是Apache Hadoop。Hadoop是首个在开源社区获得极大关注的大数据处理框架,其原生的MapReduce引擎,主要采取的“分而治之”的分布式计算模式。
MapReduce,将一个分布式计算过程拆解成两个阶段:
Map阶段,由多个可并行执行的Map Task构成,主要功能是将待处理数据集按照数据量大小切分成等大的数据分片,每个分片交由一个任务处理。
Reduce阶段,由多个可并行执行的Reduce Task构成,主要功能是,对前一阶段中各任务产生的结果进行规约,得到最终结果。

即使过去了这么多年,Hadoop在基础架构上仍然占据重要位置,但是MapReduce引擎,作为Hadoop原生计算引擎,却受到诟病:
比如:编程模型抽象程度较低,仅支持Map和Reduce两种操作;Map的中间结果需要写入磁盘,多个MR之间需要使用HDFS交换数据,不适合迭代计算(机器学习、图计算)等。但是,作为最早的大数据处理引擎,Hadoop MapReduce值得被铭记。
流处理模式:而流处理模式的代表框架,就不得不提到Apache Storm了。
Storm是一种侧重于低延迟的流处理框架,以近实时方式处理源源不断的流数据。Storm的基本思想是使用spout拉取stream(数据),并使用bolt进行处理和输出,Storm数据处理延时可以达到亚秒级。
批处理 流处理模式:随着大数据的进一步发展,单纯的批处理与单纯的流处理框架,其实都是不能完全满足企业当下的需求的,由此也就开始了批处理 流处理共同结合的混合处理模式。
批处理 流处理的典型代表框架,那就不得不说Apache Spark。Spark是基于Hadoop MapReduce计算模型的优化,Spark通过内存计算模型和执行优化大幅提高了对数据的处理能力(在不同情况下,速度可以达到MR的10-100倍,甚至更高)。
而Spark的流处理能力,则是由Spark Streaming模块提供的。Spark引入微批次(Micro-Batch)的概念,即把一小段时间内的接入数据作为一个微批次来处理。但是与Storm等原生的流处理系统相比,Spark Streaming的延时会相对高一些。

Apache Flink同样支持流处理和批处理,FLink的设计思想,是“有状态的流计算”,将逐项输入的数据作为真实的流处理,将批处理任务当作一种有界的流来处理。
在目前的流数据处理框架领域,Flink可谓独树一帜。虽然Spark同样也提供了批处理和流处理的能力,但Spark流处理的微批次架构使其响应时间略长。Flink流处理优先的方式实现了低延迟、高吞吐和真正逐条处理,这也是这几年Flink越来越受到重视的原因所在。
关于大数据计算模式,批处理&流处理,以上就为大家做了简单的介绍了。大数据处理,不管是批处理、流处理还是两者结合的混合处理,从根本上来说,还是需要根据不同的数据类型和数据需求来进行技术选型的。
,