感知机与多层网络
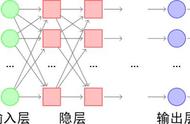
感知机(Perceptron)是由两层神经元组成的一个简单模型,但只有输出层是M-P神经元,即只有输出层神经元进行激活函数处理,也称为功能神经元(functionalneuron);输入层只是接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数目),而没有激活函数。这样一来,感知机与之前线性回归的思想基本是一样的,都是通过对属性加权与另一个常数求和,再使用sigmoid函数将这个输出值压缩到0-1之间,从而解决分类问题。不同的是感知机的输出层应该可以有多个神经元,从而可以实现多分类问题,同时两个模型所用的参数估计方法十分不同。
给定训练集,则感知机的n 1个参数(n个权重 1个阈值)都可以通过学习得到。阈值Θ可以看作一个输入值固定为-1的哑结点的权重ωn 1,即假设有一个固定输入xn 1=-1的输入层神经元,其对应的权重为ωn 1,这样就把权重和阈值统一为权重的学习了。简单感知机的结构如下图所示:

感知机权重的学习规则如下:对于训练样本(x,y),当该样本进入感知机学习后,会产生一个输出值,若该输出值与样本的真实标记不一致,则感知机会对权重进行调整,若激活函数为阶跃函数,则调整的方法与Logistic回归类似(基于梯度下降法)。
感知机是通过逐个样本输入来更新权重,首先设定好初始权重(一般为随机),逐个地输入样本数据,若输出值与真实标记相同则继续输入下一个样本,若不一致则更新权重,然后再重新逐个检验,直到每个样本数据的输出值都与真实标记相同。容易看出:感知机模型总是能将训练数据的每一个样本都预测正确,和决策树模型总是能将所有训练数据都分开一样,感知机模型很容易产生过拟合问题。
由于感知机模型只有一层功能神经元,因此其功能十分有限,只能处理线性可分的问题,对于这类问题,感知机的学习过程一定会收敛(converge),因此总是可以求出适当的权值。
BP神经网络算法
由上面可以得知:神经网络的学习主要蕴含在权重和阈值中,多层网络使用上面简单感知机的权重调整规则显然不够用了,BP神经网络算法即误差逆传播算法正是为学习多层前馈神经网络而设计,BP神经网络算法是迄今为止最成功的的神经网络学习算法。
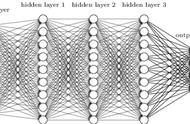
一般而言,只需包含一个足够多神经元的隐层,就能以任意精度逼近任意复杂度的连续函数,故下面以训练单隐层的前馈神经网络为例,介绍BP神经网络的算法思想。

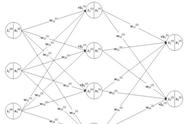
上图为一个单隐层前馈神经网络的拓扑结构,BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度方向对权重进行调节。可以看出:BP算法首先将误差反向传播给隐层神经元,调节隐层到输出层的连接权重与输出层神经元的阈值;接着根据隐含层神经元的均方误差,来调节输入层到隐含层的连接权值与隐含层神经元的阈值。BP算法基本的推导过程与感知机的推导过程原理是相同的,下面给出调整隐含层到输出层的权重调整规则的推导过程:

BP算法的最终目标是要最小化整个训练集D上的累积误差