监听自身模式
在这里,不写入数据库的原因在于避免双重写入。当进入消息系统之后,消息会在完全独立的事务上下文中进入服务 B,也会重新返回服务 A。通过这样一个曲折的处理流程,服务 A 和服务 B 就可以独立地处理请求,并写入到各自的数据库中了。
并行管道的优点和缺点
表 5:并行管道的优点和缺点
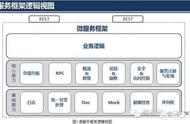
如何选择分布式事务策略从本文的论述中,你可能已经猜到,在微服务架构中,处理分布式事务并没有正确或错误的模式。每种模式都有其优点和缺点。每种模式都能解决一些问题,但是反过来又会产生其他的问题。图 12 中的图表简单总结了我所阐述的各种双重写入模式的主要特征。

双重写入模式的特征
不管你采用哪种方式,都要阐述和记录决策背后的动机,以及该选择在架构上所带来的长期影响。你还需要得到从长期实现和维护该系统的团队那里获取支持。在这里,我根据数据一致性和可扩展性特征来组织和评估本文所描述的各种方法,如图 13 所示。

各个双重写入模式的数据一致性和可扩展性特征
我们从可扩展性最强、可用性最高的方法到可扩展性最差、可用性最低的顺序来评估各种方法。
高:并行管道和协同式如果你的步骤在时间上是解耦的,那么采用并行管道的方法来运行是很合适的。有可能你只能在系统的某些部分使用这种模式,而不是在整个系统中。接下来,假设步骤间存在时间方面的耦合性,特定的操作和服务必须要在其他的服务前执行,那么你可以考虑采用协同式的方式。借助协同式的服务,我们可以创建一个可扩展的、事件驱动的架构,在这里消息会通过一个去中心化的协同化过程在服务和服务之间流动。在这种情况下,使用 Debezium 和 Apache Kafka 的发件箱模式实现(如Red Hat OpenShift Streams for Apache Kafka)特别有趣,而且越来越受欢迎
中等:编排式和两阶段提交如果协同式模式不是很合适,你需要一个负责协调和决策的中心点,那么可以考虑采用编排式模式。这是一个流行的架构,有基于标准的和自定义的开源实现。基于标准的实现可能会强迫你使用某些事务语义,而自定义的编排式实现则允许你在所需的数据一致性和可扩展性之间进行权衡。
低:模块化单体如果你沿着图示再往左走的话,那么很可能你对数据一致性有非常强烈的需求,而且对它所需的重大权衡有充分的思想准备。在这种情况下,针对特定数据源,通过两阶段提交的分布式事务是可行的,但是在专门为可扩展性和高度可用性设计的动态云环境中,它很难可靠地实现。如果是这样的话,那么你可以直接采用比较老式的模块化单体方式,同时伴以从微服务运动中学到的实践。这种方式可以确保最高的数据一致性,但代价是运行时和数据源的耦合。
结论在具有数十个服务的大型分布式系统中,并不会有一个适用于所有场景的方式,我们需要将其中的几个方法结合起来,应用于不同的环境中。我们可能会将几个服务部署在一个共享的运行时上,以满足对数据一致性的特殊需求。我们可能会选择两阶段的提交来与支持 JTA 的遗留系统进行集成。我们可能会编排复杂的业务流程,并让其余的服务使用协同式模式和并行处理。总而言之,你选择什么策略并不重要,重要的是基于正确的原因,精心选择一个策略,并执行它。