本文最初发表于 RedHat 博客网站,经原作者 Bilgin Ibryam 授权由 InfoQ 中文站翻译分享。
作为 Red Hat 咨询架构师,我有幸参与了大量客户项目。虽然每个客户都面临自己特有的挑战,但是我发现其中有一些共同点。大多数项目都想知道如何协调对多个记录系统的写入。要回答这个问题,一般会涉及长篇累牍的解释,包括双重写入(dual write)、分布式事务、现代化的替代方案以及每种方式可能出现的故障情况和缺点。这样做通常会让客户意识到,将单体应用拆分为微服务架构是一个漫长和复杂的过程,而且通常都需要权衡。
本文不会深入介绍事务的细节,而是总结了向多个数据源协调写入操作的主要方式和模式。我知道,你可能对这些方法有过美好或糟糕的经验。但是实践中,在正确的环境和正确的限制条件下,这些方法都能很好地工作。技术领导者要为自己的环境选择最好的方式。
双重写入的问题关于你是否会面临双重写入的问题有一个简单的指标,那就是预期要不要向多个记录系统进行写入操作。这样的需求可能并不明显,在分布式系统设计的过程中,它可能会以不同的方式进行表述。比如说:
- 你已经为每项工作选择了最佳工具,现在在一个业务事务中,你必须要更新一个 NoSQL 数据库、一个搜索索引和一个缓存。
- 你所设计的服务必须要更新自己的数据库,同时还要把变更相关的信息以通知的形式发送给另一个服务。
- 你的业务事务跨越了多个服务的边界。
- 你可能需要以幂等的方式实现服务操作,因为服务的消费者必须要重试失败的调用。
在本文中,我们将会使用一个很简单的示例场景来评估在分布式事务中处理双重写入的各种方法。我们的场景是一个客户端应用,它会在发生变更操作的时候,调用一个微服务。服务 A 要更新自己的数据库,但是它还要调用服务 B 进行写入操作,如图 1 所示。至于数据库的实际类型以及服务与服务之间进行交互的协议,这些对于我们的讨论都无关紧要,因为问题都是一样的。

微服务中的双重写入问题
我们简要解释一下为什么这个问题没有简单的解决方案。如果服务 A 写入到了自己的数据库,然后发送一个通知到队列中供服务 B 使用(我们将这种方式称为 local-commit-then-publish),这样应用依然有可能无法可靠地运行。当服务 A 写入到自己的数据库,然后发送消息到队列时,依然有很小的概率发生这样的事情,即应用在提交到数据库后,且在第二个操作之前,发生了崩溃,这样的话,就会使系统处于一个不一致的状态。如果消息在写入到数据库之前发送的话(我们将这种方式称为 publish-then-local-commit),有可能出现数据库写入失败,或者服务 B 接收到事件的时候,服务 A 还没有提交到数据库,这会出现时效性问题。不管是出现哪种情况,这种场景都会涉及到对数据库和队列的双重写入问题,这就是我们要探讨的核心问题。在下面的章节中,我们将会讨论针对这一长期存在的挑战目前已有的各种解决方案。
模块化单体将应用程序开发为模块化单体看起来像一种权宜之计(hack),或是架构演化的一种倒退。但是,我发现它在实践中能够很好地运行。它不是一种微服务的模式,而是微服务规则的一个例外情况,能够非常严谨地与微服务相结合。如果强写入一致性是驱动性的需求,甚至要比独立部署和扩展微服务的能力更重要时,那么我们就可以采用模块化单体的架构。
采用单体架构并不意味着系统设计得很差或者是件坏事。它并不说明任何质量相关的问题。顾名思义,这是一个按照模块化方式设计的系统,它只有一个部署单元。需要注意,这是一个精心设计和实现的模块化单体,这与随意创建并随时间而不断增长的单体是不同的。在精心设计的模块化单体架构中,每个模块都遵循微服务的原则。每个模块会封装对其数据的所有访问,但是操作是以内存方法调用的方式进行暴露和消费的。
模块化单体的架构如果采用这种方式的话,我们必须要将两个微服务(服务 A 和服务 B)转换成可以部署到共享运行时的库模块(library module)。然后,让这两个微服务共享同一个数据库实例。因为服务是在一个通用的运行中编写和部署的,所以它们可以参与相同的事务。鉴于这些模块共享同一个数据库实例,所以我们可以使用本地事务一次性地提交或回滚所有的变更。在部署方法方面也有差异,因为我们希望模块以库的方式部署到一个更大的部署单元中,并参与现有的事务。
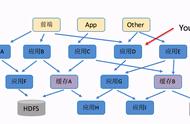
即便是在单体架构中,也有一些方式来隔离代码和数据。例如,我们可以将模块隔离成单独的包、构建模块和源码仓库,这些模块可以由不同的团队所拥有。通过将表按照命名规则、模式、数据库实例,甚至数据库服务器的方式进行分组,我们可以实现数据的部分隔离。图 2 的灵感来源于 Axel Fontaine 关于伟大的模块化单体的演讲,它阐述了应用中不同的代码和数据隔离级别。

应用程序的代码和数据隔离级别
拼图的最后一块是使用一个运行时和一个包装器服务(wrapper service),该服务能够消费其他的模块并将其纳入到现有事务的上下文中。所有的这些限制使模块比典型的微服务耦合更紧密,但是好处在于包装器服务能够启动一个事务、调用库模块来更新它们的数据库,并且以一个操作的形式提交或回滚事务,而不必担心部分失败或最终一致性的问题。
在我们的样例中,如图 3 所示,我们将服务 A 和服务 B 转换为库,并将它们部署到一个共享的运行时中,或者也可以将其中的某个服务作为共享运行时。数据库的表也共享同一个数据库实例,但是它会被拆分为一组由各自的库服务管理的表。