前言
机器学习 作为人工智能领域的核心组成,是计算机程序学习数据经验以优化自身算法,并产生相应的“智能化的”建议与决策的过程。
一个经典的机器学习的定义是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
一、机器学习概论
机器学习是关于计算机基于数据分布构建出概率统计模型,并运用模型对数据进行分析与预测的方法。按照学习数据分布的方式的不同,主要可以分为监督学习和非监督学习:

1.1 监督学习
从有标注的数据(x为变量特征空间, y为标签)中,通过选择的模型及确定的学习策略,再用合适算法计算后学习到最优模型,并用模型预测的过程。模型预测结果Y的取值有限的或者无限的,可分为分类模型或者回归模型;

1.2 非监督学习:
从无标注的数据(x为变量特征空间),通过选择的模型及确定的学习策略,再用合适算法计算后学习到最优模型,并用模型发现数据的统计规律或者内在结构。按照应用场景,可以分为聚类,降维和关联分析等模型;

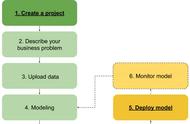
二、机器学习建模流程