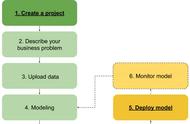
2.1 明确业务问题
明确业务问题是机器学习的先决条件,这里需要抽象出现实业务问题的解决方案:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
(如一个简单的新闻分类场景就是学习已有的新闻及其类别标签数据,得到一个分类模型,通过模型对每天新的新闻做类别预测,以归类到每个新闻频道。)

2.2 数据选择:收集及输入数据
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。意味着数据的质量决定了模型的最终效果,在实际的工业应用中,算法通常占了很小的一部分,大部分工程师的工作都是在找数据、提炼数据、分析数据。数据选择需要关注的是:
① 数据的代表性:无代表性的数据可能会导致模型的过拟合,对训练数据之外的新数据无识别能力;
② 数据时间范围:监督学习的特征变量X及标签Y如与时间先后有关,则需要明确数据时间窗口,否则可能会导致数据泄漏,即存在和利用因果颠倒的特征变量的现象。(如预测明天会不会下雨,但是训练数据引入明天温湿度情况);
③ 数据业务范围:明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音;
2.3 特征工程:数据预处理及特征提取
特征工程就是将原始数据加工转化为模型有用的特征,技术手段一般可分为:
数据预处理:特征表示,缺失值/异常值处理,数据离散化,数据标准化等;特征提取:特征衍生,特征选择,特征降维等;
- 特征表示数据需要转换为计算机能够处理的数值形式。如果数据是图片数据需要转换为RGB三维矩阵的表示。

字符类的数据可以用多维数组表示,有Onehot独热编码表示、word2vetor分布式表示及bert动态编码等;

- 异常值处理收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。通常需要对人为引起的异常值进行处理,通过业务判断和技术手段(python、正则式匹配、pandas数据处理及matplotlib可视化等数据分析处理技术)筛选异常的信息,并结合业务情况删除或者替换数值。
- 缺失值处理数据缺失的部分,通过结合业务进行填充数值、不做处理或者删除。根据缺失率情况及处理方式分为以下情况:① 缺失率较高,并结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;② 缺失率较低,结合业务可使用一些缺失值填充手段,如pandas的fillna方法、训练随机森林模型预测缺失值填充;③ 不做处理:部分模型如随机森林、xgboost、lightgbm能够处理数据缺失的情况,不需要对缺失数据做任何的处理。
- 数据离散化数据离散化能减小算法的时间和空间开销(不同算法情况不一),并可以使特征更有业务解释性。离散化是将连续的数据进行分段,使其变为一段段离散化的区间,分段的原则有等距离、等频率等方法。
- 数据标准化数据各个特征变量的量纲差异很大,可以使用数据标准化消除不同分量量纲差异的影响,加速模型收敛的效率。常用的方法有:① min-max 标准化:将数值范围缩放到(0,1),但没有改变数据分布。max为样本最大值,min为样本最小值。② z-score 标准化:将数值范围缩放到0附近, 经过处理的数据符合标准正态分布。u是平均值,σ是标准差。
- 特征衍生
基础特征对样本信息的表述有限,可通过特征衍生出新含义的特征进行补充。特征衍生是对现有基础特征的含义进行某种处理(组合/转换之类),常用方法如:
① 结合业务的理解做衍生,比如通过12个月工资可以加工出:平均月工资,薪资变化值,是否发工资 等等;
② 使用特征衍生工具:如feature tools等技术;
- 特征选择
特征选择筛选出显著特征、摒弃非显著特征。特征选择方法一般分为三类: