本文根据数美科技李田老师在2018年 DataFun AI Talk中分享的《机器学习在数美业务上的落地》编辑整理而成。
导读:今天分享的内容有数美科技在机器学习领域用到的技术以及落地应用碰到的一些问题,落地应用和paper上面区别很大,有时限于工程问题会对其进行功能上的改进或者是一些妥协。首先讲机器学习三大领域,然后介绍数美业务中数美天信、数美天网、数美天净业务中用到的机器学习方法和所做的一些妥协。
01
机器学习三大领域

机器学习分为三大领域,首先是监督学习,主要应用场景有分类场景和评分场景。在业务中有很多业务需求,如需要对一个人行为进行评分来判断是否拦截。数美业务有:天信 - 可信度评分,天网 - 客户评分/广告行为分,天净 - 涉政、涉黄、涉恐、涉暴的内容识别与拦截。数美各项业务中常见的算法有逻辑回归、决策树,以及当下比较流行的xgboost,分类场景的大*器,各项kaggle比赛的宠儿,大量应用于生产实践上。还有就是一些深度学习算法,如DNN、CNN,以及与序列学习相关的RNN。
第二个领域就是无监督学习,这在反欺诈中是比较重要的技术。很多时候跟黑产对抗的时候,黑产变化我们也得变化,但是反欺诈的成本远远高于黑产的成本,因此很难用监督学习的方法跟上黑产的脚步。异常点监测、离群分析、关联挖掘提供了一种更好的非人工方式,正常人在互联网里无论是社交行为还是购买行为、对话等有自己的一个passion,黑产有一种不同于正常人的行为,是很罕见、奇怪的做法,可以通过技术将其抓取出来。主要的业务有反欺诈、反作弊,最基础的聚类算法,在各项聚类中作为baseline——K-means,目前业内较为流行的发现异常/离群簇算法,且不会对簇形状有要求——DBSCAN,还有Iforest是高效的异常点发掘算法,将数据用一棵树来表针,还能区分哪些叶子节点算异常节点哪些不算。

第三个领域是增强学习,目前还没有太多应用,目前比较流行的算法有Q-learning及其各项衍生、MCTS 蒙特卡洛树搜索、RHGA滚动遗传算法。这几类算法有一个约束就是它需要一个playreview,游戏AI、自动驾驶、智能机器人的playreview是很好定义的。游戏怎么玩都是知道,自动驾驶的目标、使用范围都是可以抽象的。但是如果用在反欺诈、漏洞分析就会存在局限性,如何将过程变为程序可理解,以及过程中存在很多随机性行为导致很难去学习。
--
02
在数美业务上落地

接下来讲三个领域具体在数美业务中的落地,首先是数美天信。
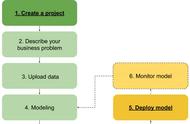
数美天信本质是用多方数据为人进行信用背书,激励人在社会上各个方面构建良好的信用记录,并使之成为人的信用资本。可信度的架构如上图所示,将数据提供方提供的数据进行结构化,有一种方法将所有提供方的数据结构放入多方来源结构数据表,然后进行统计策略上分析,或者监督学习的方法进行模型制定,将策略和模型进行线上部署,当客户对一个人进行查询时通过选择模型策略对用户进行信用评估。原先评分卡做法就是IOE、WOE、AR等,我们有所保留有所突破,也会用同样的方法来判断对目标的贡献,也有自己的模式做这些东西。
传统模式评分卡分为三步做特征、选特征、训模型,做特征主要是某段时间你干了什么事,某一类事情干了多少次。然后进入选特征,尽量将特征做的少一点、简单一点便于可控,主要特征有IP、WOE、行为数据等,还有依据Xgboost生成树的节点选择特征。最后依据选出的特征做模型。做特征是一个开放的过程,你需要去猜测那些特征可能对我们的评分有贡献,然后在选特征时测试那些对我们实际有用的特征。由于这个过程人的介入太多了,所以采用序列化模式做这些事情。构造这个人的事件序列,如金融中一个例子,你先注册、申请、批款,将这种以序列的方式进行模型训练,就不用考虑那么多特征,还有一些其他优点,如部署方面的优点,后续会介绍到。