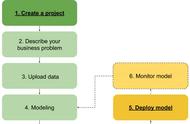
选自horace博客
作者:Horace He
机器之心编译
编辑:Juniper
深度学习是门玄学?也不完全是。
每个人都想让模型训练得更快,但是你真的找对方法了吗?在康奈尔大学本科生、曾在 PyTorch 团队实习的 Horace He 看来,这个问题应该分几步解决:首先,你要知道为什么你的训练会慢,也就是说瓶颈在哪儿,其次才是寻找对应的解决办法。在没有了解基本原理(第一性原理)之前就胡乱尝试是一种浪费时间的行为。
在这篇文章中,Horace He 从三个角度分析可能存在的瓶颈:计算、内存带宽和额外开销,并提供了一些方式去判断当前处于哪一个瓶颈,有助于我们更加有针对性地加速系统。这篇文章得到了陈天奇等多位资深研究者、开发者的赞赏。

以下是原文内容:
怎样才能提高深度学习模型的性能?一般人都会选择网上博客中总结的一些随机技巧,比如「使用系统内置的运算算子,把梯度设置为 0,使用 PyTorch1.10.0 版本而不是 1.10.1 版本……」
在这一领域,当代(特别是深度学习)系统给人的感觉不像是科学,反而更像炼丹,因此不难理解用户为什么倾向于采用这种随机的方法。即便如此,这一领域也有些第一性原理可以遵循,我们可以据此排除大量方法,从而使得问题更加容易解决。
比如,如果你的训练损失远低于测试损失,那么你可能遇到了「过拟合」问题,而尝试着增加模型容量就是在浪费时间。再比如,如果你的训练损失和你的验证损失是一致的,那对模型正则化就显得不明智了。
类似地,你也可以把高效深度学习的问题划分为以下三个不同的组成部分:
- 计算:GPU 计算实际浮点运算(FLOPS)所花费的时间;
- 内存:在 GPU 内传输张量所花费的时间;
- 额外开销:花在其它部分的时间。
在训练机器学习模型的时候,知道你遇到的是哪类问题非常关键,使模型高效的问题也是如此。例如,当模型花费大量时间进行内存到 GPU 的转移的时候(也就是内存带宽紧张的时候),增加 GPU 的 FLOPS 就不管用。另一方面,如果你正在运行大量的矩阵乘法运算(也就是计算紧张的时候),将你的程序重写成 C 去减轻额外开销就不会管用。
所以,如果你想让 GPU 丝滑运行,以上三个方面的讨论和研究就是必不可少的。

惨痛教训的背后有大量工程师保持 GPU 高效运行。
注意:这个博客中的大多数内容是基于 GPU 和 PyTorch 举例子的,但这些原则基本是跨硬件和跨框架通用的。
计算
优化深度学习系统的一个方面在于我们想要最大化用于计算的时间。你花钱买了 312 万亿次浮点数运算,那你肯定希望这些都能用到计算上。但是,为了让你的钱从你昂贵的矩阵乘法中得到回报,你需要减少花费在其他部分的时间。
但为什么这里的重点是最大化计算,而不是最大化内存的带宽?原因很简单 —— 你可以减少额外开销或者内存消耗,但如果不去改变真正的运算,你几乎无法减少计算量。
与内存带宽相比,计算的增长速度增加了最大化计算利用率的难度。下表显示了 CPU 的 FLOPS 翻倍和内存带宽翻倍的时间 (重点关注黄色一栏)。

一种理解计算的方式是把它想象成工厂。我们把指令传达给我们的工厂(额外消耗),把原始材料送给它(内存带宽),所有这些都是为了让工厂运行得更加高效(计算)。