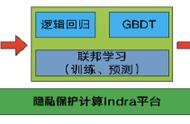
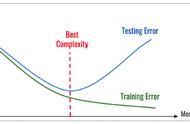
数据准备
为方便进行模型间的比对,本文使用的数据集只包括北京997个重点区域在2020/01/17至2020/02/15这30天内每个小时的人群密度数据,总共717840条记录。数据包含三个维度,分别是区域ID、时间戳和人群密度指数,数据格式如图1所示。

图1 训练样本示例
训练数据和测试数据都以小时为最小时间步,其中部分区域30天内的人群密度指数趋势如图2所示:

图2部分重点区域30天内人群密度指数趋势
在进行时间序列预测建模之前,首先要进行时间序列的自相关性分析,确定训练数据是符合时间序列要求的。时间序列的自相关性可以理解为时间序列自己与自己(不同滞后项)之间的相关性,本文使用时滞图来观察时间序列的自相关性,时滞图是把时间序列的值及相同序列在时间轴上后延的值放在一起展示,如图3所示。

图3 部分重点区域人群密度指数时滞图
通过观察时滞图发现,各区域的人群密度指数都在对角线附近聚集,存在明显的正相关性,说明各区域的人群密度指数序列符合时间序列的要求,可以使用相关的模型进行预测。为了方便评估模型,总共30天的数据中,选择前27天的数据作为训练集进行模型训练,后3天的数据作为测试集进行模型测试。